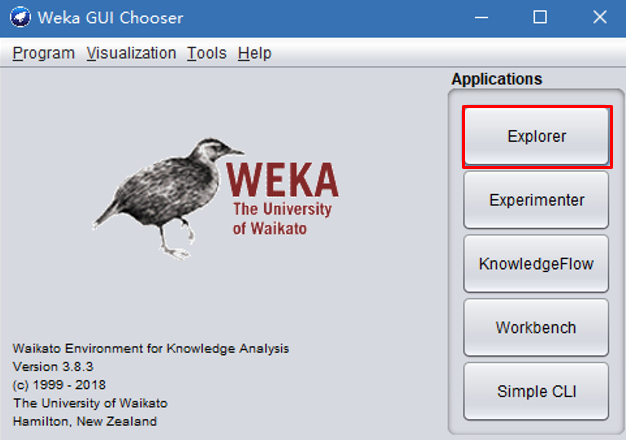
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。Weka是用Java写成的,它可以运行于几乎所有的操作平台,包括Linux,Windows等操作系统。Weka平台提供一个统一界面,汇集了当今最经典的机器学习算法及数据预处理工具。做为知识获取的完整系统,包括了数据输入、预处理、知识获取、模式评估等环节,以及对数据及学习结果的可视化操作。并且可以通过对不同的学习方法所得出的结果进行比较,找出解决当前问题的最佳算法。WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过http://www.cs.waikato.ac.nz/ml/weka得到。如果想自己实现数据挖掘算法的话,可以看一看weka的接口文档。在weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。2005年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的Weka小组荣获了数据挖掘和知识探索领域的最高服务奖,Weka系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一(已有11年的发展历史)。打开weka,点击Explorer进入操作界面。
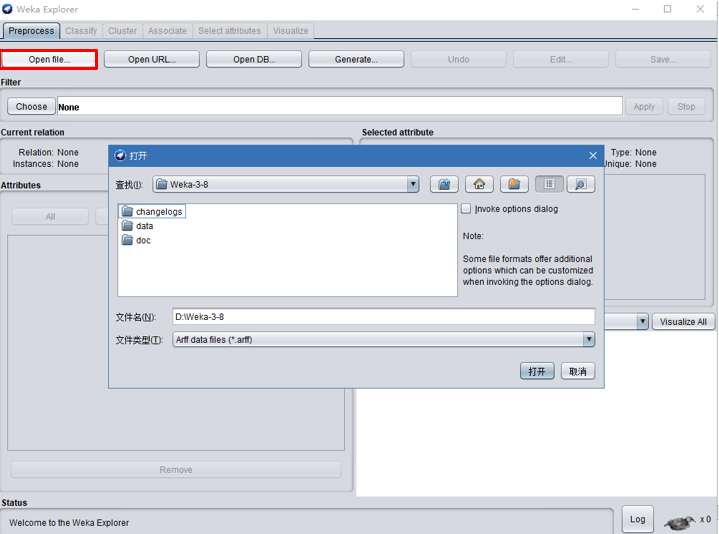
进入主界面后,点击Open file,选择需要挖掘的数据,找到安装weka的路径(路径为:/opt/weka)。
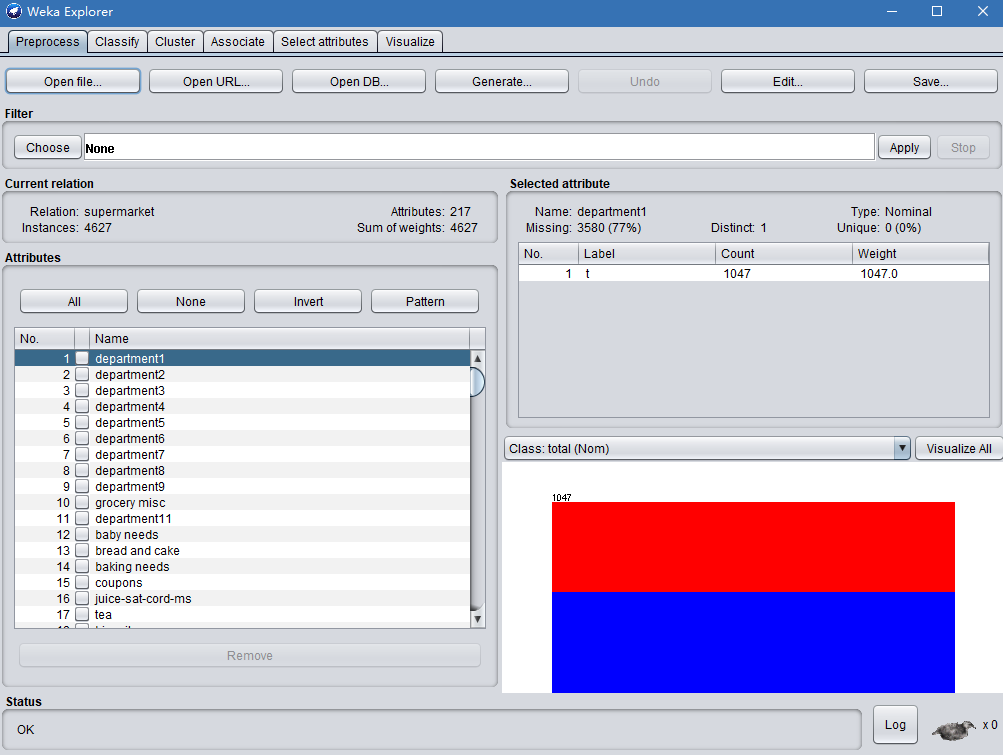
weka的路径下面的data文件夹中有自带的数据集,选择supermarket.arff数据集。arff格式是weka专用的文件格式,全称Attribute-Relation File Format。它是一个ASCII文本文件,记录了一些共享属性的实例。表格里的横行称作一个实例,竖行称作一个属性,这样的一个数据集,呈现了属性之间的一种关系。supermarket.arff数据集是一个超市购物篮分析数据集,其中数据是从新西兰的一个真实超市收集得到。
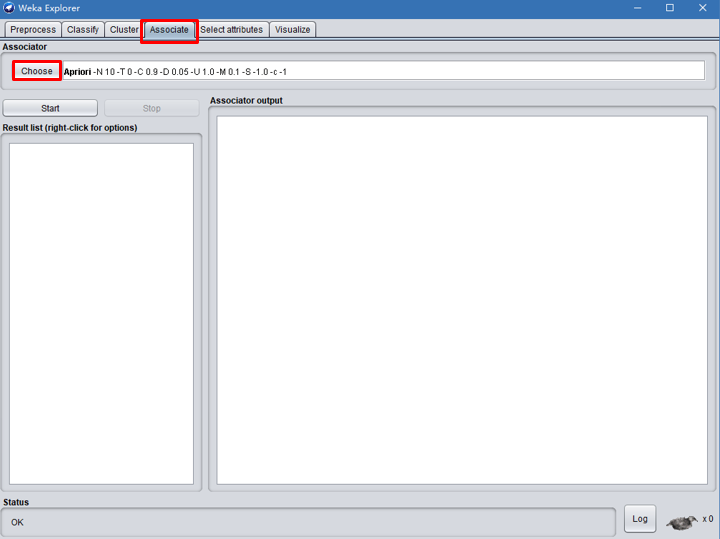
关联规则是数据挖掘的热点之一。关联规则反映一个对象与其他对象之间的相互依赖性,如果多个对象之间存在一定的关系,那么一个对象就能够通过其他对象来进行预测。关联规则可以采用与分类规则相同的方式产生。由于得到的关联规则的数量庞大,通常需要通过使用覆盖率和准确率进行修剪,覆盖率也称为支持度,指的是应用规则之后预测正确的实例数量。准确率也称为置信度,表示为支持度数值应用规则后的数量比例。点击Associate后点击choose选择相关算法。
选择Apriori算法。Apriori算法的基本思想是:首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频集,使用了递归的方法。
点击choose旁边的部分设置参数。
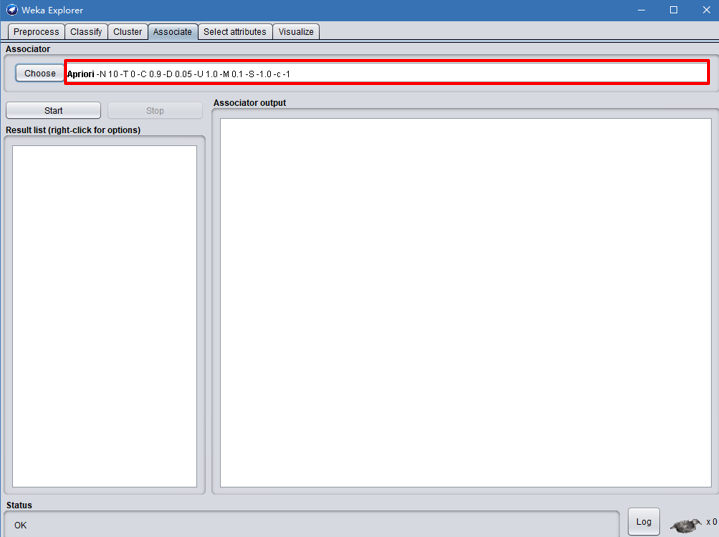
点击之后会看到参数设置界面,参数主要是选择支持度(lowerBoundMinSupport),规则评价机制(metriType)及对应的最小值minMetric(指度量类型),设置对规则进行排序的度量依据。可以是:置信度(support),提升度(lift),杠杆率(leverage),确信度(conviction),注意:类关联规则只能用置信度挖掘。点击OK保存设置结果。
设置好参数后点击start运行。
可以看到Apriori的运行结果:
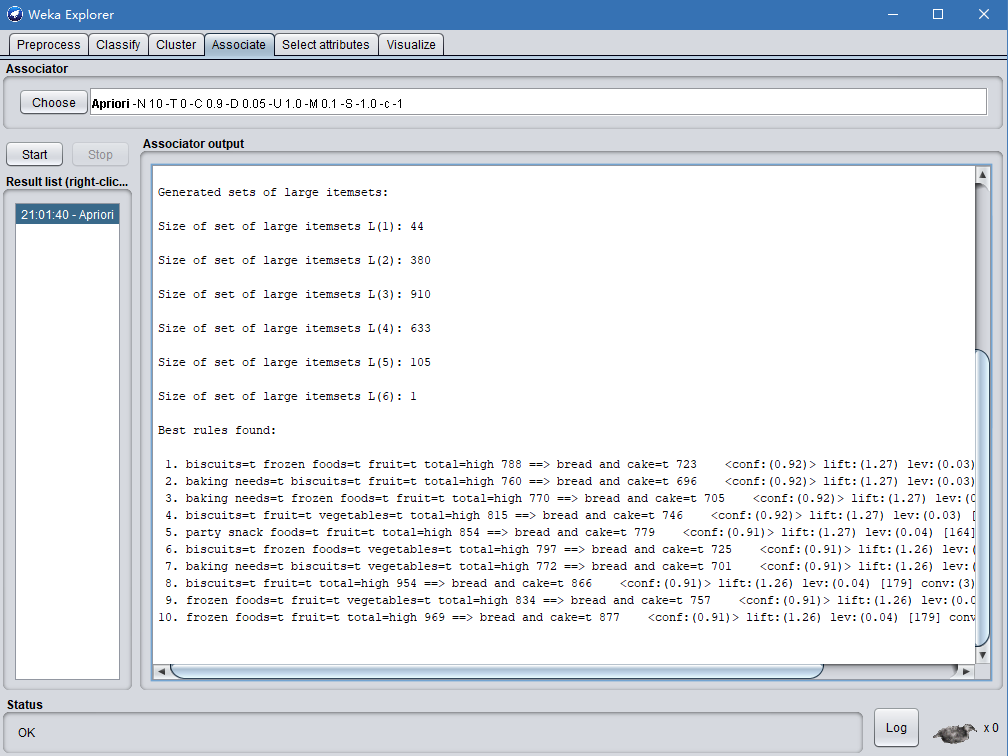
该样本数据的实验结果是,频繁1项集44个,频繁2项集380个,频繁3项集910个,频繁4项集633个,频繁5项集105个,频繁6项集1个。得到最佳关联规则,每条规则都带有项集出现次数、置信度、相关度等数值。如:1. biscuits=t frozen foods=t fruit=t total=high 788 ==> bread and cake=t 723 conf:(0.92) lift:(1.27) lev:(0.03) [155] conv:(3.35) 中biscuits、frozen foods、fruit是一个好的关联规则并且记录数是12,其中置信度为0.92,提升度为1.27,杠杆率为0.03,确信度为3.35。


