双击Weka图标,打开软件,在初始界面中点击“Explorer”,并打开Weka自带的数据集“diabetes.arff”(768条实例数据)。
点击“Open file”选项,查找到Weka目录下的“data”文件夹,找到其中的“diabetes.arff”文件,点击右下角的打开选项。
(请确保你已经安装上一步骤打开目标文件,否则请先按步骤打开目标文件)切换到“Cluster”,点击“Choose”按钮,选择目录下的“SimpleKMeans”,这是WEKA中实现的K均值聚类的算法。
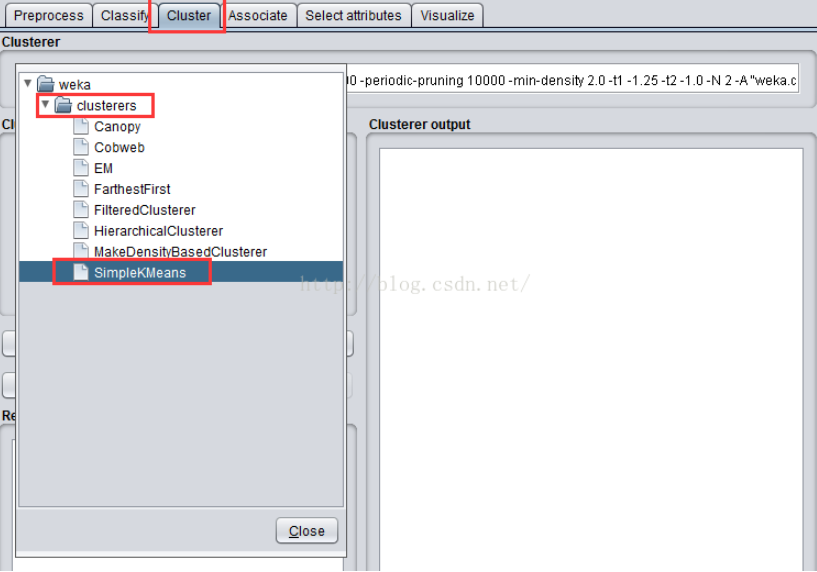
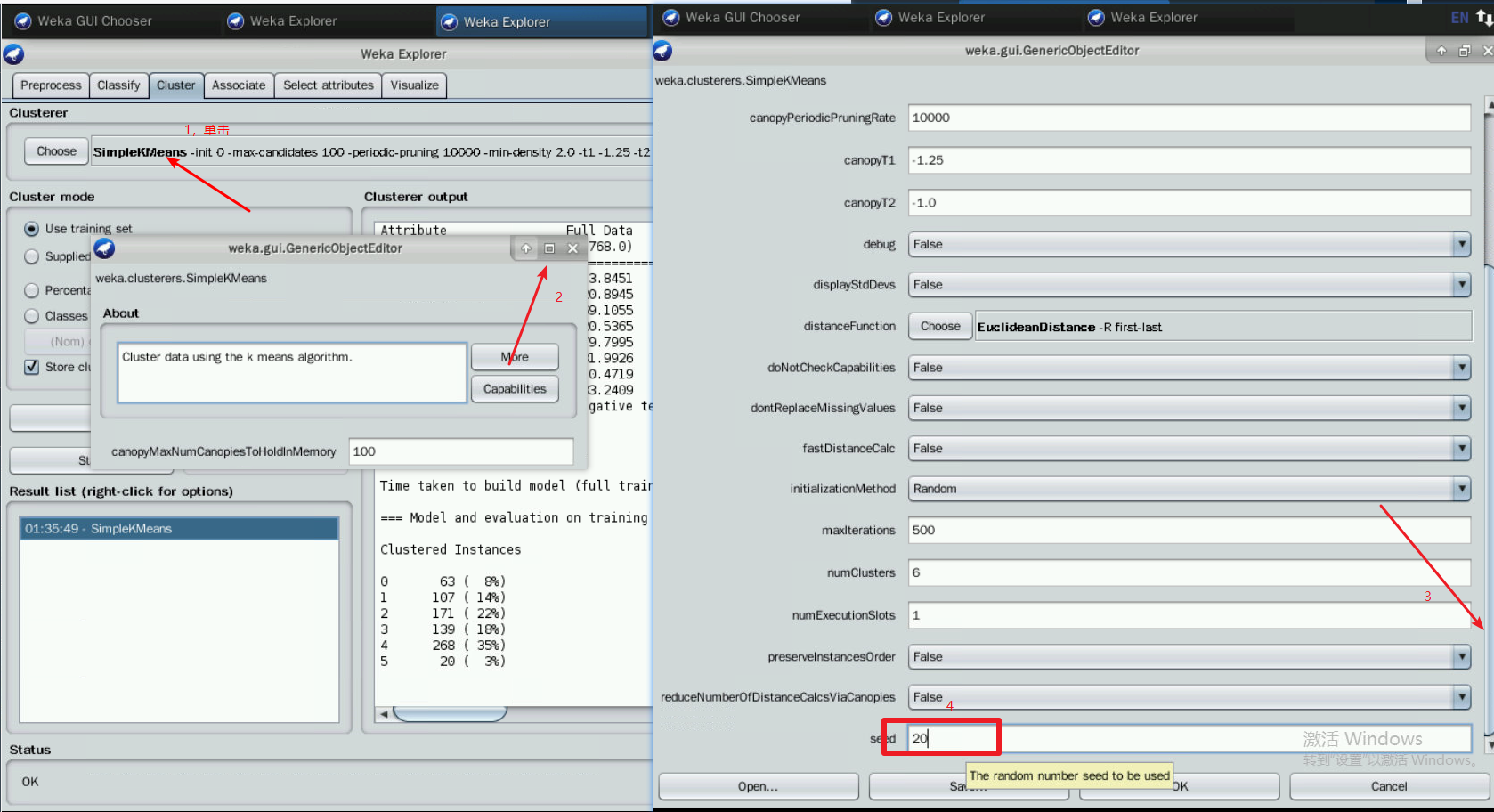
点击“Choose”旁边的文本框,修改“numClusters”为6,说明我们希望把这768条实例聚成6类,即K=6;下面的“seed”参数是要设置一个随机种子 ,依此产生一个随机数 ,用来得到K均值算法中第一次给出的K个簇中心的位置。我们不妨暂时让它就为10,点击OK。
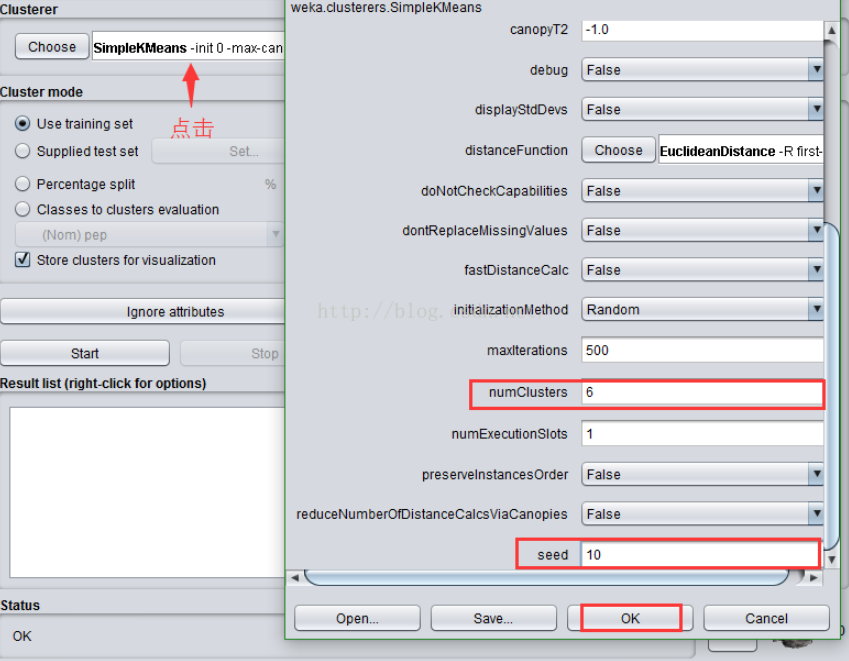
选中“Cluster Mode”的“Use training set”(使用训练集),选择“Store clusters for visualization”(存储聚类可视化),点击“Start”按钮。

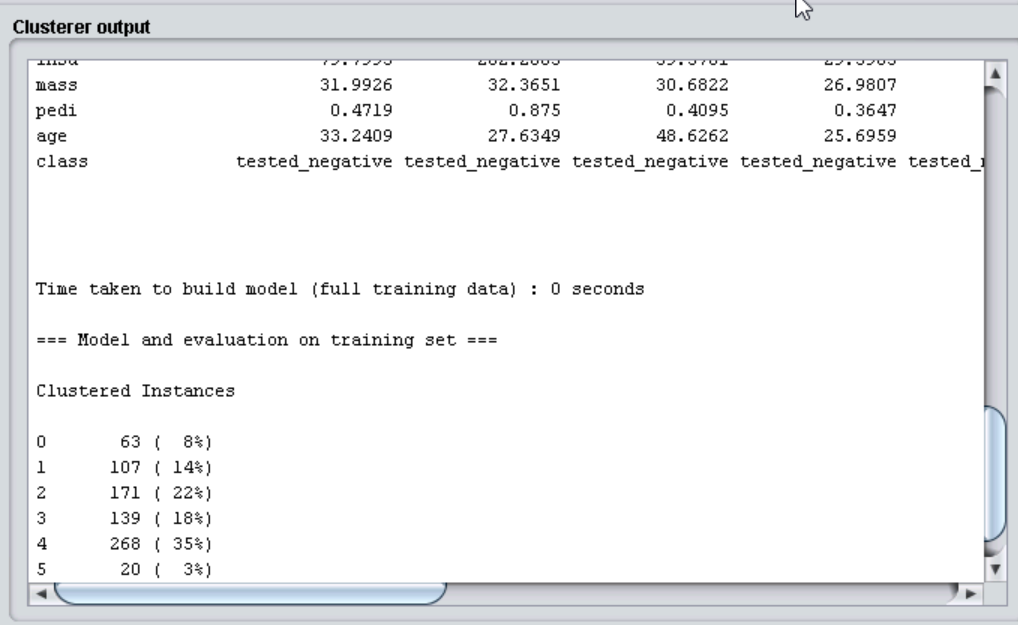
点击“Start”按钮之后,观察右边窗口“Clusterer output”给出的聚类结果。也可以在左下角“Result list”中这次产生的结果上点右键,选择“View in separate window”,然后在新窗口中浏览结果,结果中的“Cluster centroids”之后列出了各个簇中心的位置。可以观察得到,最终聚类实例分为6类,分别为0,1,2,3,4,5,对应的每一类实例所占比重也在后面有标注。例如第一类共有63条数据实例,占总数据的8%。如下图所示:
对于数值型的属性,簇中心就是它的均值(Mean);对于分类型的属性,簇中心就是它的众数(Mode),也就是说这个属性上取值为众数值的实例最多;对于数值型的属性,还给出了该属性在各个簇中的标准差(Std Devs)。比如第一行数据为“preg”的属性,后面的几列数据分别代表其在所有数据和6个簇中的簇中心数值,下面的几行则是其他属性对应的簇中心数值。如下图所示:
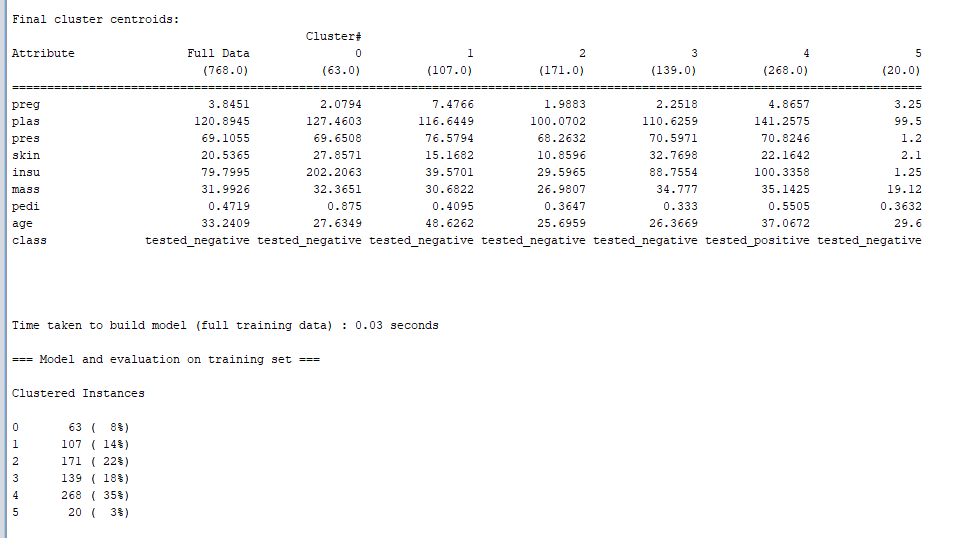
注意到结果中有这么一行(误差平方和): Within cluster sum of squared errors: 110.23525958855677。这是评价聚类好坏的标准,数值越小说明同一簇实例之间的距离越小。
将“seed”值修改为“20”,再次运行。观察结果,可以发现: Within cluster sum of squared errors: 99.80911137649608,与上面的运行过程相比数值变小。

说明同一簇实例之间的距离变小了。再尝试几个seed,这个数值可能会更小。该数值越小,说明同一簇实例直接的距离越小,聚类的结果也就越好。多次试验,找到该值趋于最小的值(实例容量越大,越难找),即得到了本次实验最好的方案结果。
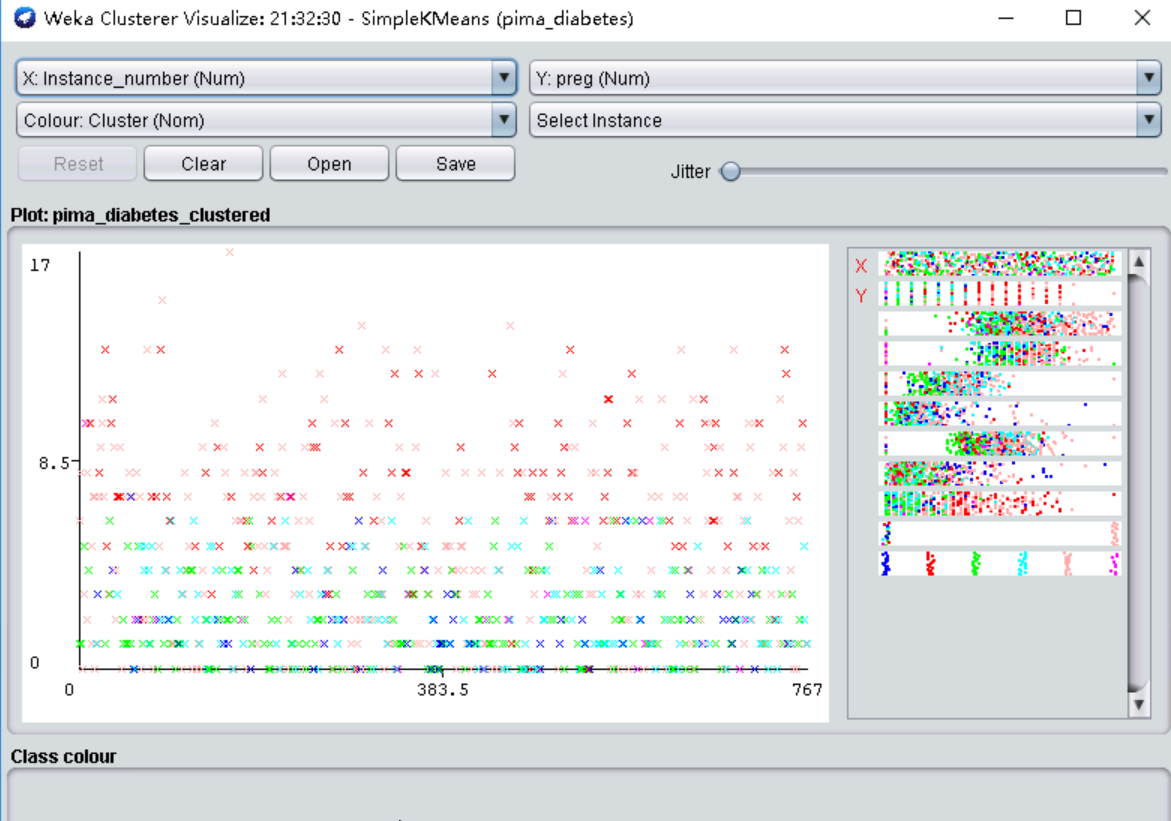
为了观察可视化的聚类结果,我们在左下方“Result list”列出的结果上右击,点“ Visualize cluster assignments”。
弹出的窗口给出了 各实例的散点图。最上方的两个框是选择横坐标和纵坐标,第二行的“color”是散点图着色的依据,默认是根据不同的簇“Cluster”给实例标上不同的颜色。可以在这里点“Save”把聚类结果保存成ARFF文件。