双击Weka图标,打开软件,在初始界面中点击“Explorer”,打开Weka自带的数据集的“iris.arff”(150条实例数据)。
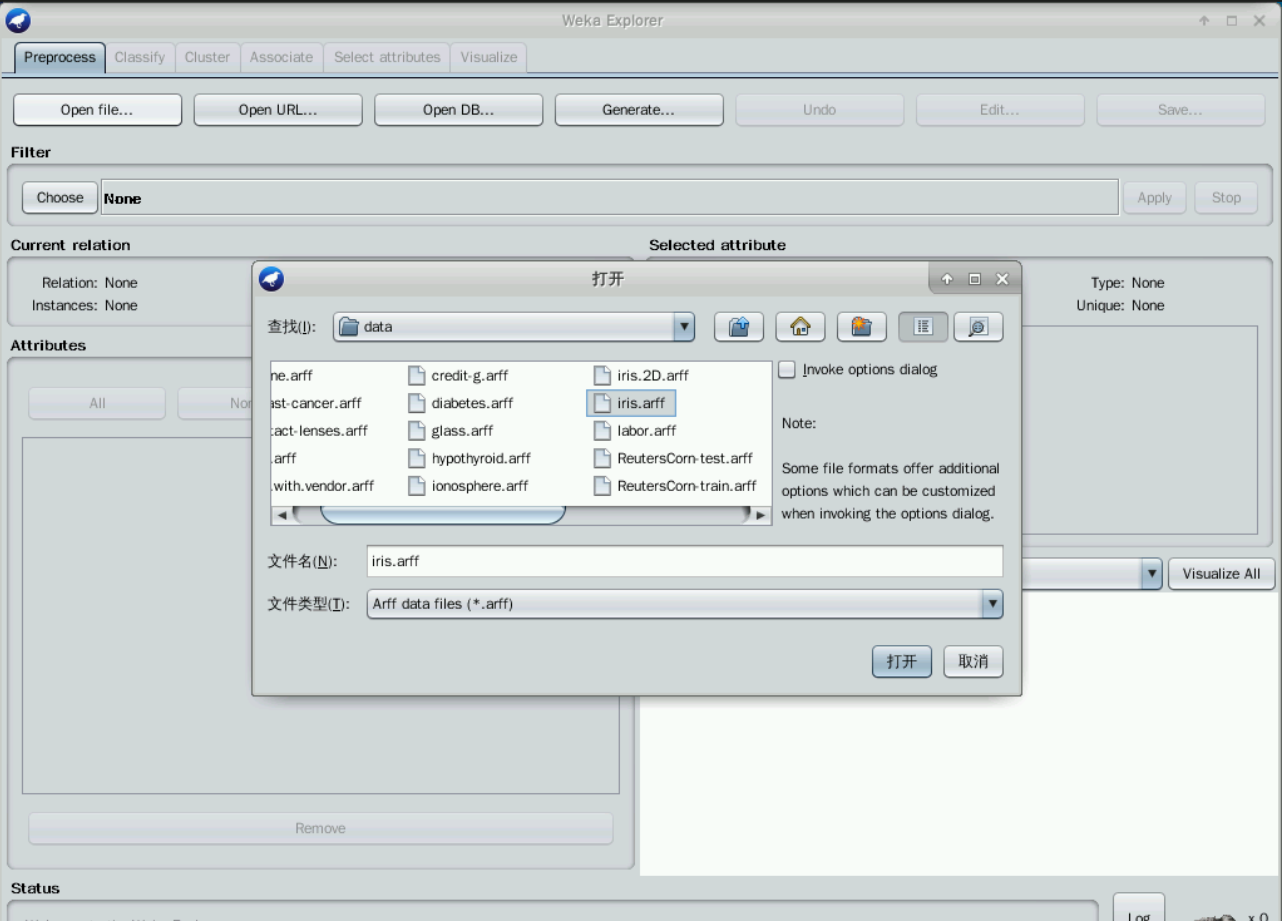
点击“Open file”选项,查找根目录位置“/opt/weka/data”,查找到Weka目录下的“data”文件夹,找到其中的“iris.arff”文件,点击右下角的打开选项。
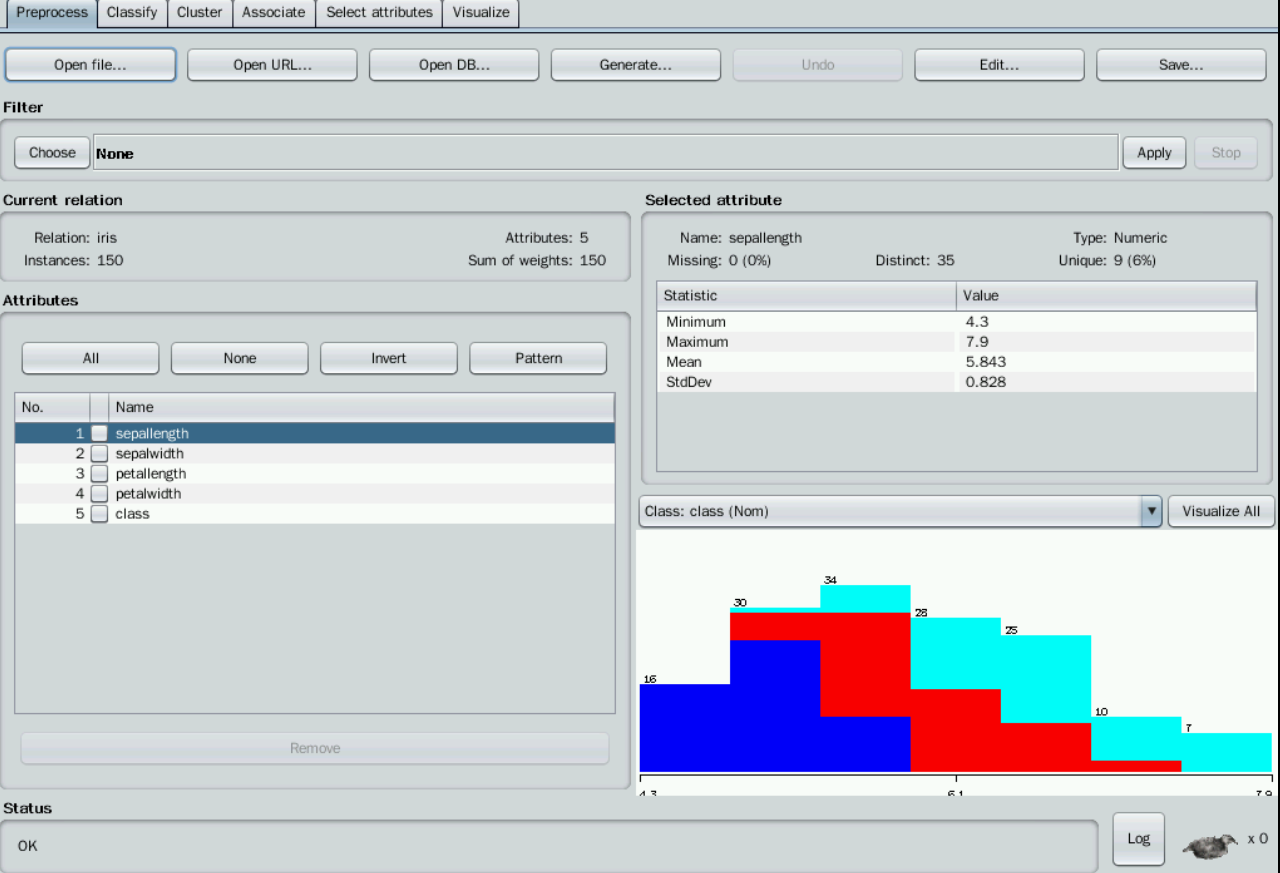
打开数据集后,界面出现该数据集的相关描述,比如:可以观察得到共有5个不同的属性,包括“sepallength”、“sepalwidth”、“petallength”、“petalwidth”和“class”,共有150条实例数据,每类数据各占多少在右下角窗口的柱状图中看到。
切换到“Cluster”,点击“Choose”按钮,选择目录下的“HierarchicalClusterer”,这是WEKA中实现层次聚类的算法。
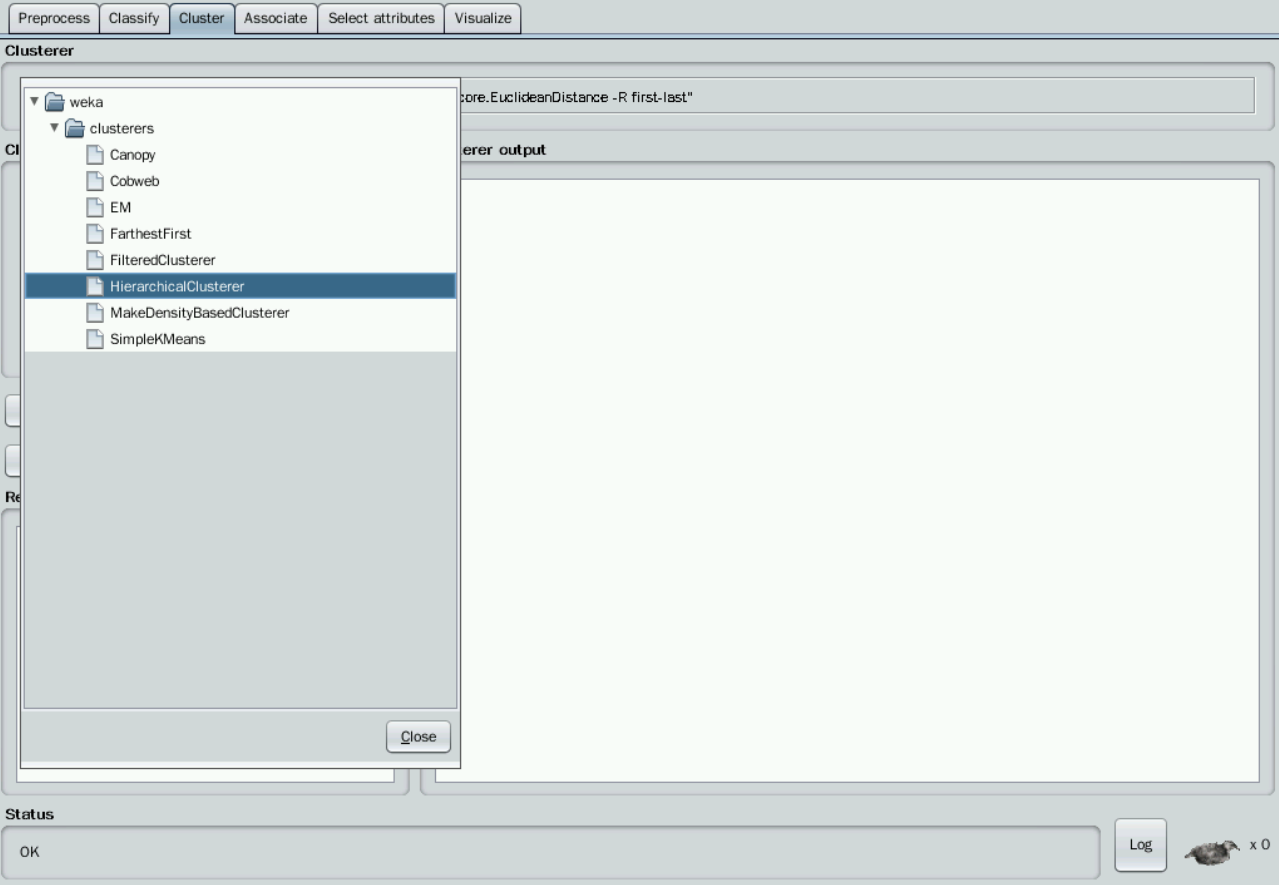
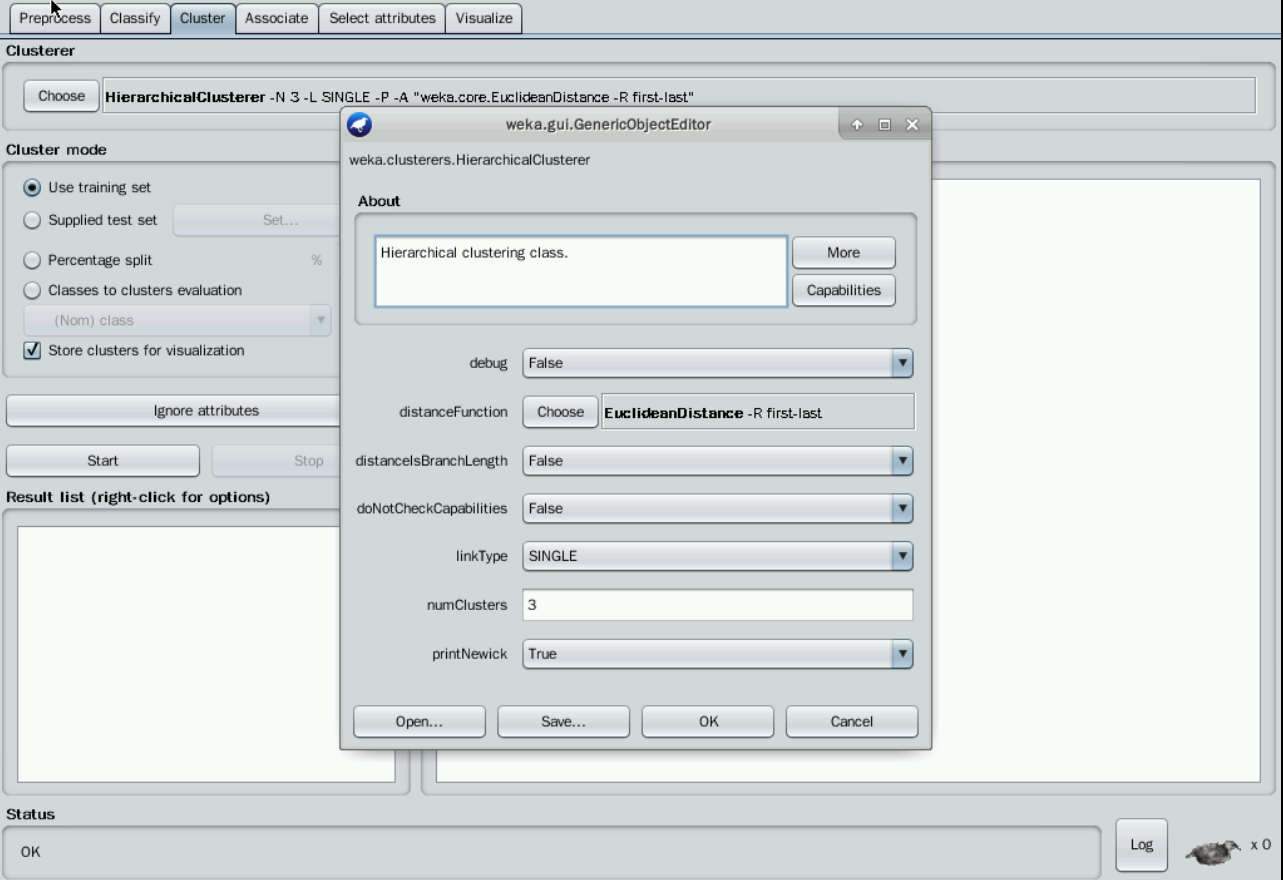
点击“Choose”旁边的文本框,修改“numClusters”为3,说明我们希望把这150条实例聚成3类,即K=3,点击OK。
选中“Cluster Mode”的“Use training set”(使用训练集),选择“Store clusters for visualization”(存储聚类可视化),点击“Start”按钮。
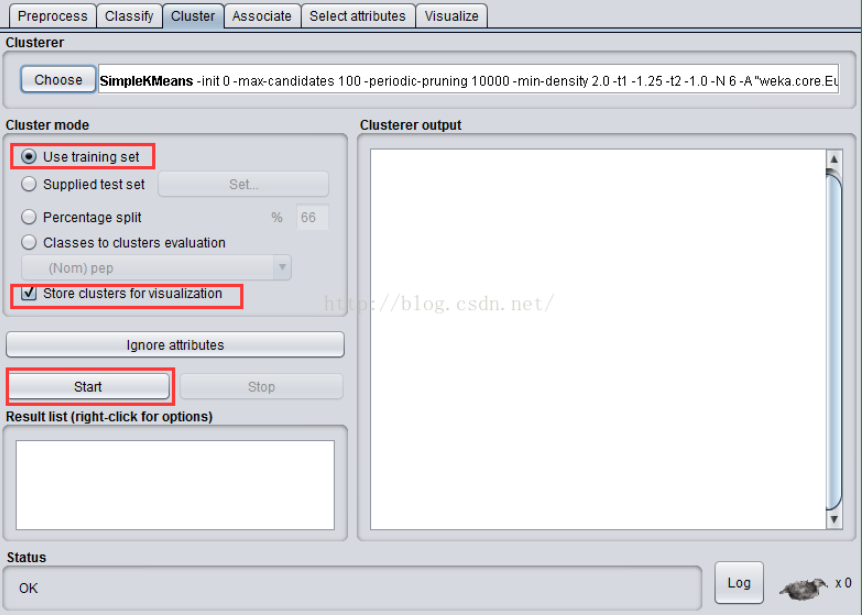
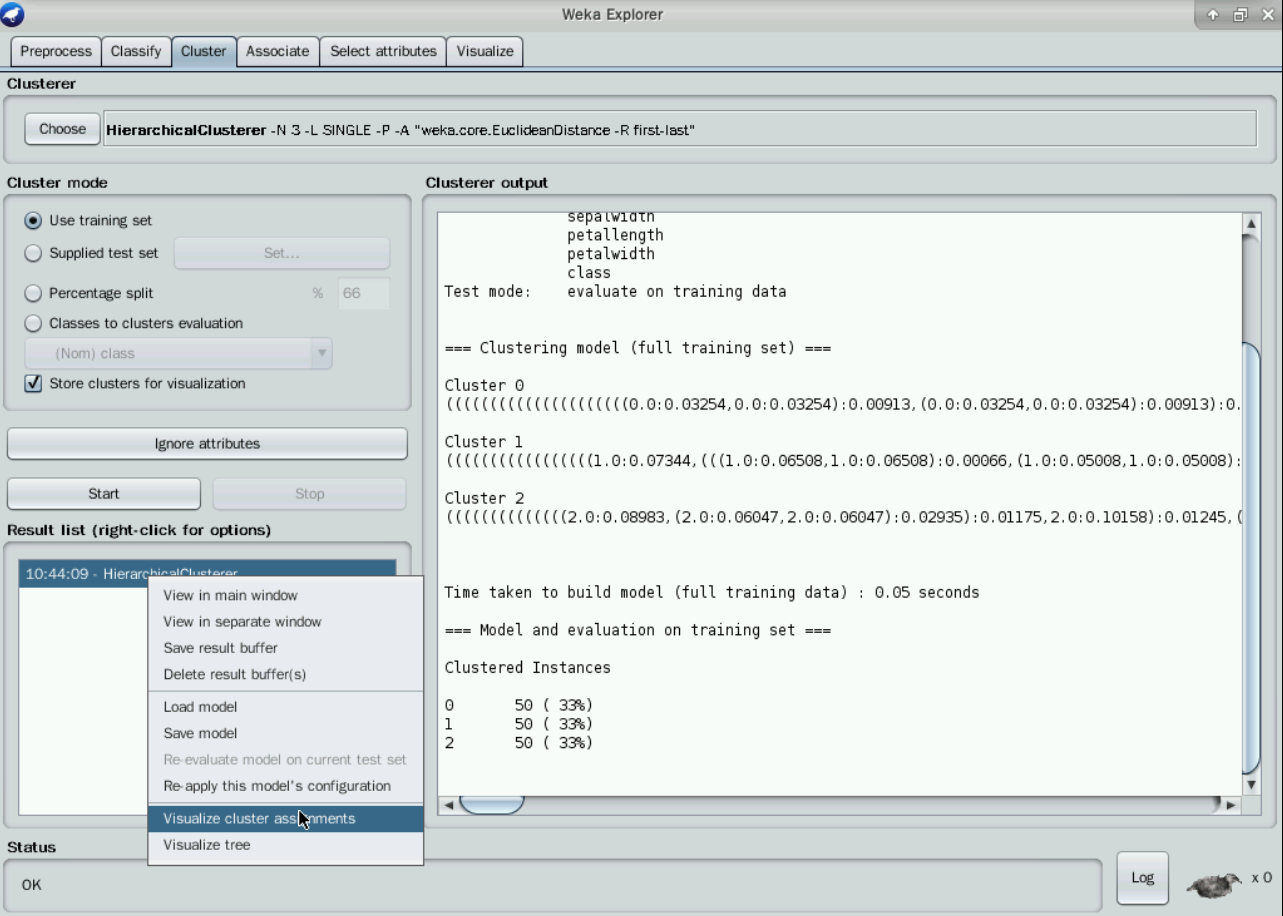
点击“Start”按钮之后,观察右边窗口“Clusterer output”给出的聚类结果。也可以在左下角“Result list”中这次产生的结果上点右键,选择“View in separate window”,然后在新窗口中浏览结果,结果中的“Cluster centroids”之后列出了各个簇中心的位置。如下图所示:
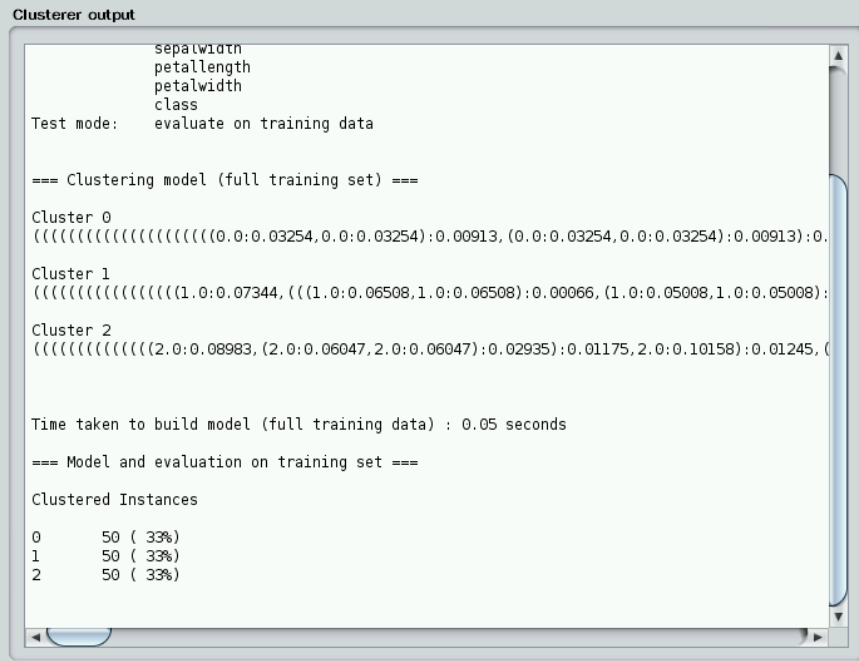
可以观察得到,最终聚类实例分为3类,分别为0,1,2,对应的每一类实例所占比重也在后面有标注。例如第一类共有50条数据实例,占总数据的33%。
为了观察可视化的聚类结果,我们在左下方“Result list”列出的结果上右击,点“ Visualize cluster assignments”。
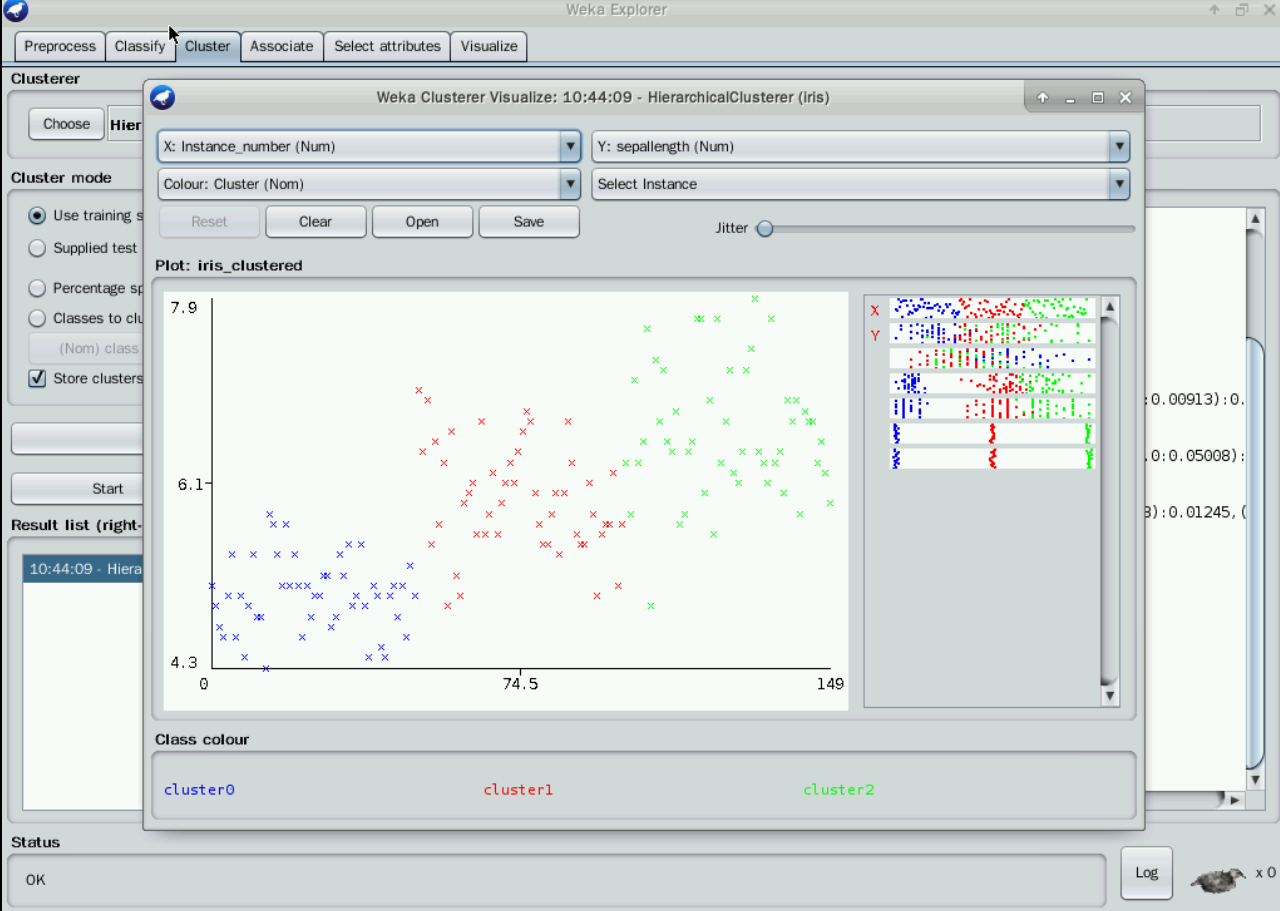
弹出的窗口给出了 各实例的散点图。最上方的两个框是选择横坐标和纵坐标,第二行的“color”是散点图着色的依据,默认是根据不同的簇“Cluster”给实例标上不同的颜色。可以在这里点“Save”把聚类结果保存成ARFF文件。