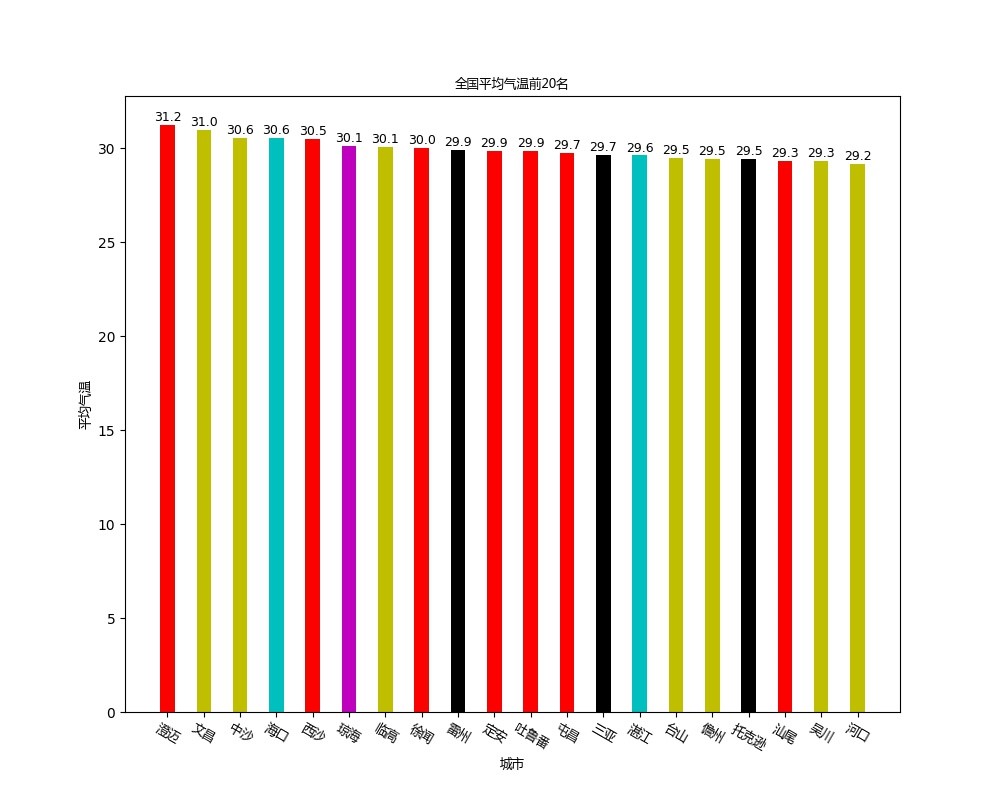
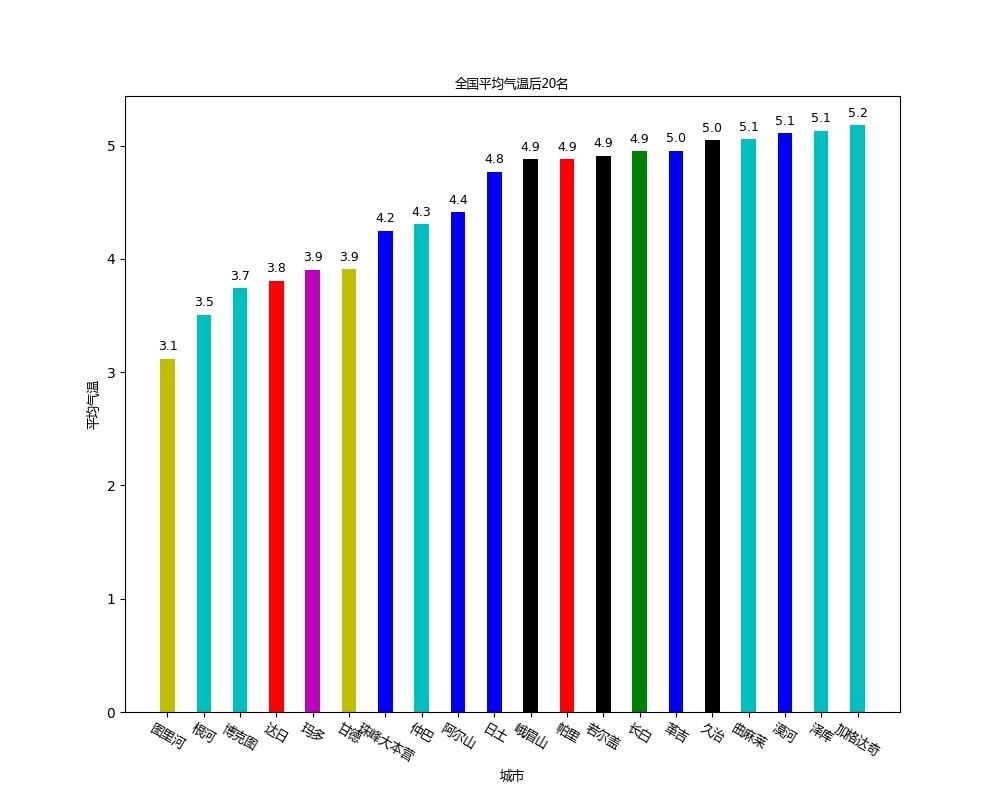
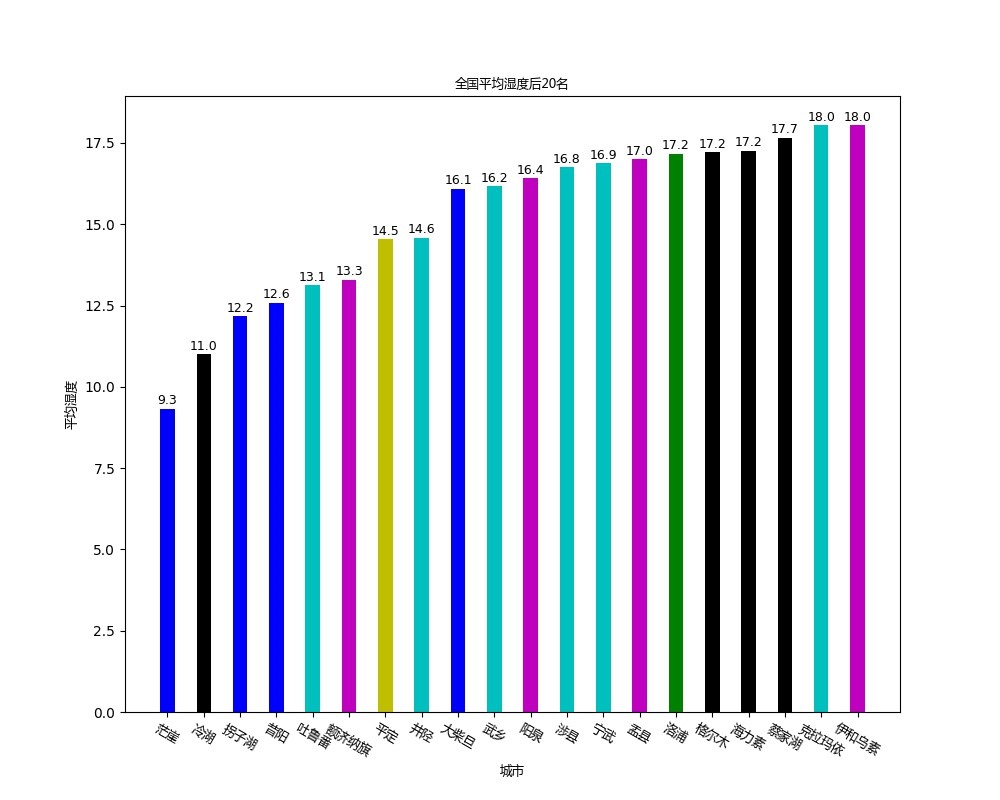
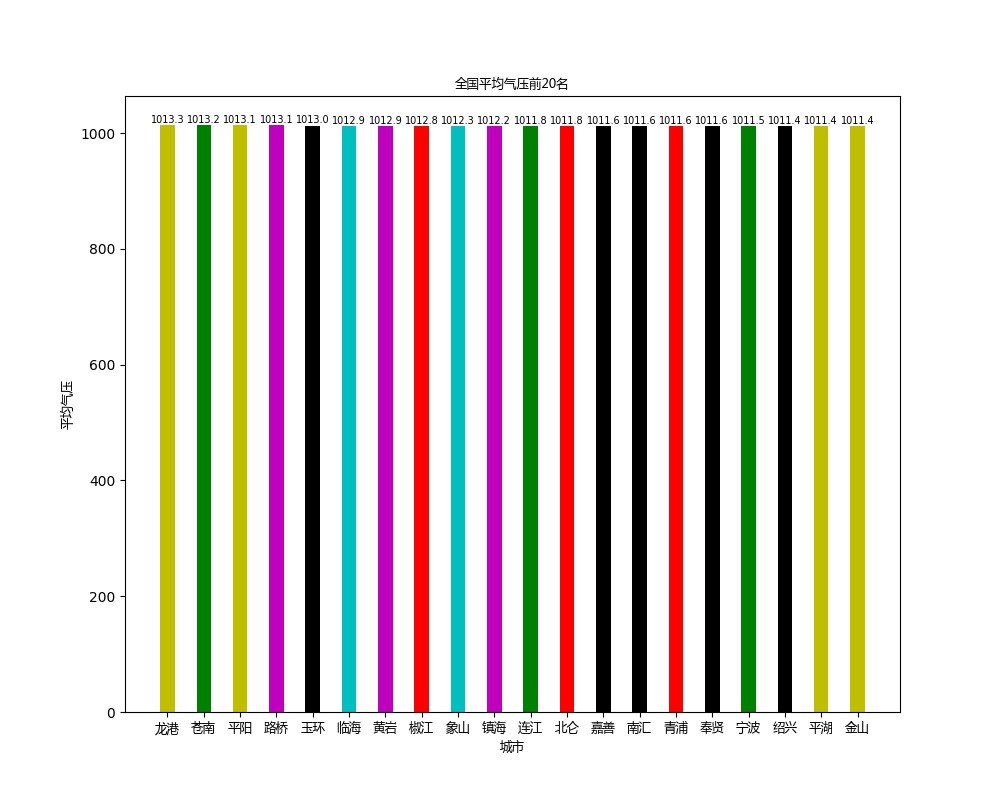
本实验针对气象数据进行分析,使用爬虫获取数据,再使用scala语言进行flink编程来处理数据,最后结果使用python进行可视化
本实验涉及到的所有数据集和代码,可以从百度网盘下载。提取码:ziyu。数据爬虫代码在数据集目录下,其余代码在源代码目录下。
Linux:Ubuntu 16.04
Python:3.8.8
VSCode:1.56
Flink:1.11.2
本实验用到的数据是中央气象台上的数据,中央气象台的网址为http://www.nmc.cn/,数据具体为每个省份的每个城市一天24小时各个小时的气温,湿度和气压。由于实验是在2021年5月25日进行的,所以具体时间是2021年5月24日的15:00到2021年5月25日的14:00。由于访问某些城市的网页时会出错,所以遇到这些城市时会采取跳过的策略,最后的城市数量为2427个,每个城市在每个时间点都有一条数据,所以总的数据条数为58248条。最后分析的结果使用python的matplotlib库展示,主要展示了平均气温最高的20个城市以及平均气温最低的20个城市,平均湿度最低的20个城市以及平均气压最高的20个城市。
通过python的requests库来获取数据。通过请求对应网址获取省份,城市以及城市天气信息,具体地:
请求省份的url:http://www.nmc.cn/f/rest/province
请求城市的url:http://www.nmc.cn/f/rest/province/ + 某省份的编码
请求城市天气等信息的url:http://www.nmc.cn/f/rest/passed/ + 某城市的编码
比如北京市的编码为ABJ,那么访问北京各个城市的url为:http://www.nmc.cn/f/rest/province/ABJ,而海淀这个城市的编码为54399,那么访问海淀这个城市的天气信息的url为:http://www.nmc.cn/f/rest/passed/54399。
在访问每个城市的近24小时天气数据时,将省份名(province),城市编号(city_number),城市(city),时间(time),温度(temperature),湿度(humidity)和气压(pressure)存储到字典变量dct中,然后将字典的值按行写入data.csv文件中。由于在请求各个城市天气信息的页面时,有的页面访问会出错,所以遇到这些页面时会采取跳过的策略。最后得到的data.csv文件里的字段信息为:province,city_number,city,time,temperature,humidity,pressure,一共有58248条数据。
代码存放在spider.py内:
import requests
import json
import csv
class Spider():
def get(self, url):
# 请求url
r = requests.get(url)
print(r.status_code)
data = json.loads(r.text) # r.text是字符串,利用json转换为列表
return data
def write_to_csv(self, data):
# province, city_number, city_name, time, temperature, humidity, pressure
dct = {}
dct['province'] = None
dct['city_number'] = None
dct['city'] = None
dct['time'] = None
dct['temperature'] = None
dct['humidity'] = None
dct['pressure'] = None
file_path = r'data.csv'
with open(file_path, 'w') as f:
w = csv.writer(f)
w.writerow(dct.keys())
city_number = 0
wrong_city = ['58357', '58151', '58981', '59989', '92024', '59554', '59362', '58964', '59354', '58965', '59152', '59162']
for province in data:
print("正在写入省份:{}".format(province['name']))
with open(file_path, 'a+') as f:
w = csv.writer(f)
province_name = province['name'] # 省份名
province_code = province['code'] # 省份编码
url_city = 'http://www.nmc.cn/f/rest/province/' + province_code # 获取省份城市的url
dct['province'] = province_name
r = requests.get(url_city)
data_city = json.loads(r.text)
for city in data_city:
city_number += 1
print("正在写入第{}个城市:{}".format(city_number, city['city']))
city_name = city['city']
city_code = city['code']
url_temperature = 'http://www.nmc.cn/f/rest/passed/' + city_code
dct['city_number'] = city_number
dct['city'] = city_name
rr = requests.get(url_temperature)
try:
data_temperature = json.loads(rr.text) # 访问出错时,把出错城市的编码记下来,然后跳过这个城市
except json.decoder.JSONDecodeError:
wrong_city.append(city_code)
city_number -= 1
continue
for temperature in data_temperature:
dct['time'] = temperature['time'][-5:]
dct['temperature'] = temperature['temperature']
dct['humidity'] = temperature['humidity']
dct['pressure'] = temperature['pressure']
w.writerow(dct.values())
print(wrong_city)
if __name__ == '__main__':
url_province = 'http://www.nmc.cn/f/rest/province' # 省份
# url_city = 'http://www.nmc.cn/f/rest/province/AFJ' # 省份的城市
# url_temperature = 'http://www.nmc.cn/f/rest/passed/59134' # 城市的24小时天气, temperature, humidity, pressure
spider = Spider()
data = spider.get(url_province)
spider.write_to_csv(data)
(1)由于data.csv里面存储的字段为province,city_number,city,time,temperature,humidity,pressure,故声明一个Record类来接受每一条数据。即:
case class Record(province:String, city_number:Int, city:String, time:String,
temperature:Double, humidity:Double, pressure:Double)
由于针对温度进行操作,故声明一个Record_temperature类来接受温度相关的参数,即:
case class Record_temperature(province:String, city_number:Int, city:String, time:String, temperature:Double)
(2)首先建立执行环境
(3)根据得到的环境的readCsvFile方法读取之前保存的data.csv文件,通过Record类来接受每一条数据,存放到csv_data里。
(4)由于未观测的数据是以9999显示的,所以要将未观测的温度数据去掉,首先将未观测温度的城市的city_number保存下来,通过csv_data运用filter算子,只要大于9998就认为该城市温度未观测到,再用map算子把每个记录改为每一个city_number,由于一个城市的24小时都有记录,所以一个城市会有24个相同的city_number,故最后运用distinct()方法去重,这样最后会得到所有的未测量温度的city_number,用remove_set存放起来。然后通过collect方法将remove_set转换为ArrayList,变量名为remove_lst。接下来就是将未测量温度的城市去掉,对csv_data调用filter算子,只要这个记录的city_number不在remove_lst中就保存这条记录,然后调用map操作将记录由Record转换为Record_temperature,保存到变量data_sort_by_temperature里。
(5)由于要求平均气温最高的20个城市,故先用groupBy算子对city_number分组,然后通过aggregate算子对每个城市的温度求和,然后通过map算子将每个城市的温度除以24得到平均温度,然后通过sortPartition按照降序对所有城市的温度进行排序,最后调用first获取前20个城市,这样就得到了平均温度最高的20个城市,存放到temperature_max20里。
(6)求平均气温最低的20个城市的操作类似,唯一不同的就是排序的时候按照升序进行排序。先用groupBy算子对city_number分组,然后通过aggregate算子对每个城市的温度求和,然后通过map算子将每个城市的温度除以24得到平均温度,然后通过sortPartition按照升序对所有城市的温度进行排序,最后调用first获取前20个城市,这样就得到了平均温度最高的20个城市,存放到temperature_min20里。
(7)最后通过writeAsCsv方法将得到的结果写入文件temperature_max20.csv和temperature_min20.csv中。
具体代码如下:
//建立执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//读取文件
val file_path = "/home/fanghan/bigdata/getdata/data.csv"
val csv_data = env.readCsvFile[Record](file_path, ignoreFirstLine = true)
//存放未测量的数据集合,未测量的值为9999.0,故大于9998则认为是未测量的值
var remove_set = csv_data.filter(x=>x.temperature>9998).map(x=>x.city_number).distinct()
//转化为ArrayList
var remove_lst = remove_set.collect()
//将未测量温度的城市去掉,然后用Record_temperature封装起来
val data_sort_by_temperature = csv_data.filter(x=>(!remove_lst.contains(x.city_number))).map(x=>Record_temperature(x.province, x.city_number, x.city, x.time, x.temperature))
//按照城市号对城市分组后对每组的城市温度进行求和,再对每个城市的温度除以24得到平均温度,然后进行排序并选取前20个平均温度最高的城市
val temperature_max20 = data_sort_by_temperature.groupBy("city_number").aggregate(Aggregations.SUM, "temperature")
.map(x=>Record_temperature(x.province, x.city_number, x.city, x.time, x.temperature/24))
.sortPartition("temperature", Order.DESCENDING)
.first(20)
//得到平均温度最低的20个城市
val temperature_min20 = data_sort_by_temperature.groupBy("city_number").aggregate(Aggregations.SUM, "temperature")
.map(x=>Record_temperature(x.province, x.city_number, x.city, x.time, x.temperature/24))
.sortPartition("temperature", Order.ASCENDING)
.first(20)
//写入文件中
temperature_max20.writeAsCsv("/home/fanghan/bigdata/getdata/temperature_max20.csv", writeMode=OVERWRITE)
temperature_min20.writeAsCsv("/home/fanghan/bigdata/getdata/temperature_min20.csv", writeMode=OVERWRITE)
(1)由于针对湿度进行操作,故声明一个Record_humidity类来接受温度相关的参数,即:
case class Record_humidity(province:String, city_number:Int, city:String, time:String, humidity:Double)
(2)由于未观测的数据是以9999显示的,所以要将未观测的湿度数据去掉,首先将未观测湿度的城市的city_number保存下来,通过csv_data运用filter算子,只要大于9998就认为该城市温度未观测到,再用map算子把每个记录改为每一个city_number,由于一个城市的24小时都有记录,所以一个城市会有24个相同的city_number,故最后运用distinct()方法去重,这样最后会得到所有的未测量温度的city_number,用remove_set存放起来。然后通过collect方法将remove_set转换为ArrayList,变量名为remove_lst。接下来就是将未测量湿度的城市去掉,对csv_data调用filter算子,只要这个记录的city_number不在remove_lst中就保存这条记录,然后调用map操作将记录由Record转换为Record_humidity,保存到变量data_sort_by_humidity里。
(3)由于要求平均湿度最低的20个城市,故先用groupBy算子对city_number分组,然后通过aggregate算子对每个城市的湿度求和,然后通过map算子将每个城市的湿度除以24得到平均湿度,然后通过sortPartition按照升序对所有城市的湿度进行排序,最后调用first获取前20个城市,这样就得到了平均湿度最低的20个城市,存放到humidity_min20里。
(4)最后通过writeAsCsv方法将得到的结果写入文件humidity_min20.csv中。
具体代码如下:
//找到未测量湿度的城市
remove_set = csv_data.filter(x=>x.humidity>9998).map(x=>x.city_number).distinct()
//转换为ArrayList
remove_lst = remove_set.collect()
//将未测量温度的城市去掉,然后用Record_humidity封装起来
val data_sort_by_humidity = csv_data.filter(x=>(!remove_lst.contains(x.city_number))).map(x=>Record_humidity(x.province, x.city_number, x.city, x.time, x.humidity))
//得到平均湿度最低的20个城市
val humidity_min20 = data_sort_by_humidity.groupBy("city_number").aggregate(Aggregations.SUM, "humidity")
.map(x=>Record_humidity(x.province, x.city_number, x.city, x.time, x.humidity/24))
.sortPartition("humidity", Order.ASCENDING)
.first(20)
//写入文件
humidity_min20.writeAsCsv("/home/fanghan/bigdata/getdata/humidity_min20.csv", writeMode=OVERWRITE)
(1)由于针对气压进行操作,故声明一个Record_pressure类来接受温度相关的参数,即:
case class Record_pressure(province:String, city_number:Int, city:String, time:String, pressure:Double)
(2)由于未观测的数据是以9999显示的,所以要将未观测的气压数据去掉,首先将未观测气压的城市的city_number保存下来,通过csv_data运用filter算子,只要大于9998就认为该城市气压未观测到,再用map算子把每个记录改为每一个city_number,由于一个城市的24小时都有记录,所以一个城市会有24个相同的city_number,故最后运用distinct()方法去重,这样最后会得到所有的未测量气压的city_number,用remove_set存放起来。然后通过collect方法将remove_set转换为ArrayList,变量名为remove_lst。接下来就是将未测量气压的城市去掉,对csv_data调用filter算子,只要这个记录的city_number不在remove_lst中就保存这条记录,然后调用map操作将记录由Record转换为Record_pressure,保存到变量data_sort_by_pressure里。
(3)由于要求平均气压最高的20个城市,故先用groupBy算子对city_number分组,然后通过aggregate算子对每个城市的气压求和,然后通过map算子将每个城市的气压除以24得到平均气压,然后通过sortPartition按照降序对所有城市的气压进行排序,最后调用first获取前20个城市,这样就得到了平均气压最高的20个城市,存放到pressure_max20里。
(4)最后通过writeAsCsv方法将得到的结果写入文件pressure_max20.csv中。
具体代码如下:
//找到未测量气压的城市
remove_set = csv_data.filter(x=>x.pressure>9998).map(x=>x.city_number).distinct()
//转换为ArrayList
remove_lst = remove_set.collect()
//将未测量气压的城市去掉,然后用Record_humidity封装起来
val data_sort_by_pressure = csv_data.filter(x=>(!remove_lst.contains(x.city_number))).map(x=>Record_pressure(x.province, x.city_number, x.city, x.time, x.pressure))
//得到平均气压最高的20个城市
val pressure_max20 = data_sort_by_pressure.groupBy("city_number").aggregate(Aggregations.SUM, "pressure")
.map(x=>Record_pressure(x.province, x.city_number, x.city, x.time, x.pressure/24))
.sortPartition("pressure", Order.DESCENDING)
.first(20)
//写入文件
pressure_max20.writeAsCsv("/home/fanghan/bigdata/getdata/pressure_max20.csv", writeMode=OVERWRITE)
数据分析代码存放在WeatherAnalysis.scala内。
画图部分使用的是python的matplotlib库,版本为3.4.1,安装命令为pip matplotlib。
1.设置字体,由于出现中文乱码的情况,所以需要设置字体,本实验使用的字体是chinese.mysh.ttf,字体大小设置为9.
2.通过pandas读取csv文件,并将列明改为[‘province’, ‘city_number’, ‘city’, ‘time’, ‘temperature’],这里以画温度为例,故最后一列为温度,如果画湿度则改为’humidity’即可,画气压改为’pressure’即可。
3.为每个城市生成对应的颜色。
4.设置画布大小为(10,8)。
5.设置x轴,y轴的主题和字体。
6.设置x轴刻度的文本,字体和旋转度,设置旋转度是为了防止文字重叠。
7.设置标题的主题和字体。
8.为每个柱子设置文本值。
9.将图片保存下来。
画图代码如下:
代码存放在draw.py内:
def draw_temperature_max():
font = FontProperties(fname='/home/fanghan/bigdata/getdata/chinese.msyh.ttf', size=9)
temperature_max20 = pd.read_csv("/home/fanghan/bigdata/getdata/temperature_max20.csv", header=None)
temperature_max20.columns = ['province', 'city_number', 'city', 'time', 'temperature']
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k']
color = []
for i in range(20):
color.append(colors[np.random.randint(7)])
plt.figure(figsize=(10,8))
plt.bar([i for i in range(1, 41, 2)], temperature_max20['temperature'], width=0.8, color=color)
plt.xticks([i for i in range(1, 41, 2)], temperature_max20['city'], fontproperties = font, rotation=-30)
plt.xlabel("城市", fontproperties = font)
plt.ylabel("平均气温",fontproperties = font)
plt.title("全国平均气温前20名", fontproperties = font)
for a,b in zip([i for i in range(1, 41, 2)], temperature_max20['temperature']):
plt.text(a, b+0.05, '%.1f' % b, ha='center', va= 'bottom',fontsize=9)
plt.show()
plt.savefig("/home/fanghan/bigdata/getdata/temperature_max20.jpg")
def draw_temperature_min():
font = FontProperties(fname='/home/fanghan/bigdata/getdata/chinese.msyh.ttf', size=9)
temperature_max20 = pd.read_csv("/home/fanghan/bigdata/getdata/temperature_min20.csv", header=None)
temperature_max20.columns = ['province', 'city_number', 'city', 'time', 'temperature']
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k']
color = []
for i in range(20):
color.append(colors[np.random.randint(7)])
plt.figure(figsize=(10,8))
plt.bar([i for i in range(1, 41, 2)], temperature_max20['temperature'], width=0.8, color=color)
plt.xticks([i for i in range(1, 41, 2)], temperature_max20['city'], fontproperties = font, rotation=-30)
plt.xlabel("城市", fontproperties = font)
plt.ylabel("平均气温",fontproperties = font)
plt.title("全国平均气温后20名", fontproperties = font)
for a,b in zip([i for i in range(1, 41, 2)], temperature_max20['temperature']):
plt.text(a, b+0.05, '%.1f' % b, ha='center', va= 'bottom',fontsize=9)
plt.show()
plt.savefig("/home/fanghan/bigdata/getdata/temperature_min20.jpg")
def draw_humidity_min20():
font = FontProperties(fname='/home/fanghan/bigdata/getdata/chinese.msyh.ttf', size=9)
temperature_max20 = pd.read_csv("/home/fanghan/bigdata/getdata/humidity_min20.csv", header=None)
temperature_max20.columns = ['province', 'city_number', 'city', 'time', 'temperature']
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k']
color = []
for i in range(20):
color.append(colors[np.random.randint(7)])
plt.figure(figsize=(10,8))
plt.bar([i for i in range(1, 41, 2)], temperature_max20['temperature'], width=0.8, color=color)
plt.xticks([i for i in range(1, 41, 2)], temperature_max20['city'], fontproperties = font, rotation=-30)
plt.xlabel("城市", fontproperties = font)
plt.ylabel("平均湿度",fontproperties = font)
plt.title("全国平均湿度后20名", fontproperties = font)
for a,b in zip([i for i in range(1, 41, 2)], temperature_max20['temperature']):
plt.text(a, b+0.05, '%.1f' % b, ha='center', va= 'bottom',fontsize=9)
plt.show()
plt.savefig("/home/fanghan/bigdata/getdata/humidity_min20.jpg")
def draw_pressure_max20():
font = FontProperties(fname='/home/fanghan/bigdata/getdata/chinese.msyh.ttf', size=9)
temperature_max20 = pd.read_csv("/home/fanghan/bigdata/getdata/pressure_max20.csv", header=None)
temperature_max20.columns = ['province', 'city_number', 'city', 'time', 'temperature']
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k']
color = []
for i in range(20):
color.append(colors[np.random.randint(7)])
plt.figure(figsize=(10,8))
plt.bar([i for i in range(1, 41, 2)], temperature_max20['temperature'], width=0.8, color=color)
plt.xticks([i for i in range(1, 41, 2)], temperature_max20['city'], fontproperties = font)
plt.xlabel("城市", fontproperties = font)
plt.ylabel("平均气压",fontproperties = font)
plt.title("全国平均气压前20名", fontproperties = font)
for a,b in zip([i for i in range(1, 41, 2)], temperature_max20['temperature']):
plt.text(a, b+0.05, '%.1f' % b, ha='center', va= 'bottom',fontsize=7)
plt.show()
plt.savefig("/home/fanghan/bigdata/getdata/pressure_max20.jpg")
可视化图片: