本实验采用Scala语言,使用大数据处理框架Flink对音乐专辑数据进行处理,并采用Python语言对分析结果进行可视化。
(1) Linux:Ubuntu 20.04
(2) Python:3.8
(3) Hadoop:3.1.3(查看安装教程)
(4) Flink:1.9.1(查看安装教程)
(5) 开发工具:IntelliJ IDEA、PyCharm
安装完上述环境后,为了支持Python可视化分析,还需要执行下面命令安装pyecharts插件:
pip install pyecharts==1.7.0
数据集albums.csv,包含10万调音乐专辑的相关数据(从百度网盘下载数据集,提取码:ziyu ),主要字段说明如下:
id:专辑编号
artist_id:音乐专辑作家编号
album_title:音乐专辑名称
genre:专辑类型
num_of_tracks:每张专辑中的单曲数量
num_of_sales:专辑销量
rolling_stone_critic:滚石网站评分
mtv_critic:全球音乐电视台评分
music_maniac_critic:音乐达人评分
cd /usr/local/hadoop
./sbin/start-dfs.sh
./bin/hdfs dfs -mkdir -p /user/rmc
./bin/hdfs dfs -put ~/albums.csv /user/rmc
采用Scala编程语言和Flink大数据处理框架对数据集“albums.csv”进行处理分析,实验完整工程文件可从百度云盘中下载获取(提取码:ziyu),下面提供实验具体操作步骤:
(1)新建IDEA工程;
(2)在/src/main目录下创建data文件夹,用于存放分析结果;
(3)在/src/main目录下创建scala文件夹,并将该文件设置为Sources Root;
(4)在/src/main/scala目录下创建flinkProcess.scala文件,用于编写数据处理代码。
本文对音乐专辑数据集“albums.csv”进行分析,包括下列几个方面:
(1)统计从2000年至2019年各类型的音乐专辑的发行数量和销量,保存至csv文件中的格式为[音乐专辑类型,发行数量,销量];
(2)按年进行划分,统计2000年至2019年每年各类型音乐专辑的发行数量,保存至csv文件中的格式为[年份,音乐专辑类型,发行数量];
(3)按年进行划分,统计2000年至2019年每年各类型音乐专辑的销售量,保存至csv文件中的格式为[年份,音乐专辑类型,销量];
(4)按音乐专辑作者进行划分,统计总销量排名前50的音乐作者在不同评分体系中的得分,某专辑得分计算公式为:(该专辑销量/该作者所有专辑的总销量)*该专辑在不同评分体系中的评分。保存至csv文件中的格式为[作家,所有专辑销量,mtv_critic,rolling_stone_critic,music_maniac_critic]
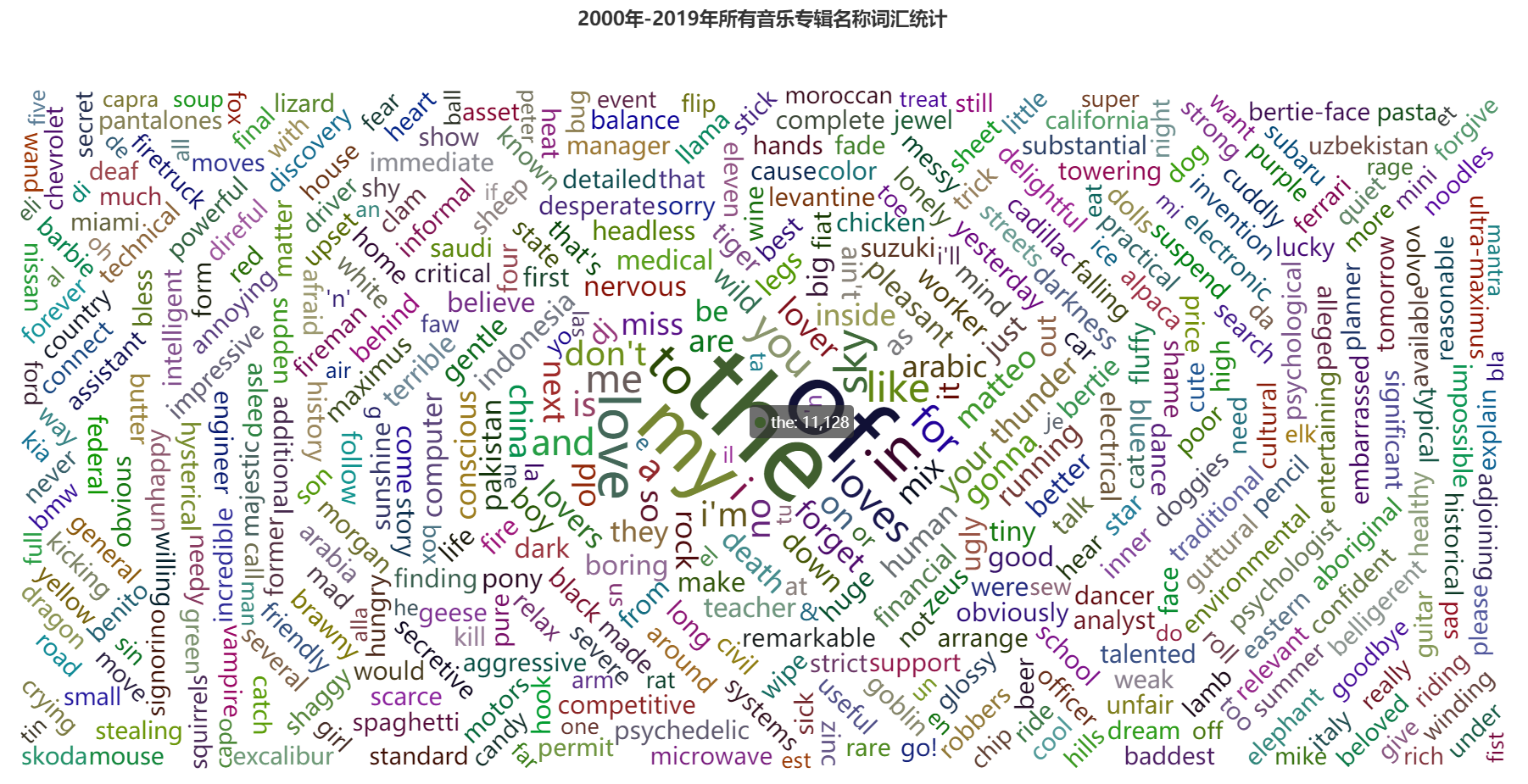
(5)分析所有专辑名称,对专辑名称中出现的词绘制词云。
4、具体代码
在flinkProcess.scala中编写以下代码:
package com.dblab
import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.scala._
/**
*
* @param id
* @param artist_id 作者编号
* @param album_title 专辑名
* @param genres 类型
* @param release 发行时间
* @param num 专辑中唱片数量
* @param sales 销售量
* @param rolling_stone_score
* @param mtv_score
* @param music_maniac_score
*/
// 定义样例类
case class Music(id: Int, artist_id: Int, album_title: String, genres: String, release: String,
num: Int, sales: Int, rolling_stone_score: Double, mtv_score: Double, music_maniac_score: Double)
object downLoad {
// 文件位置
// 本地文件位置
val DATA_PATH = "src/main/data/albums.csv"
// HDFS文件系统文件位置
val HDFS_PATH = "hdfs://localhost:9000/user/rmc/albums.csv"
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 设置并行度
env.setParallelism(1)
// 读取数据
val data: DataSet[Music] = env.readCsvFile[Music](DATA_PATH, ignoreFirstLine = true)
// 处理数据
releaseNumOfYear(data)
releaseNumAndSalesOfGenre(data)
salesOfGenreAndYear(data)
frequencyOfTitle(data)
salesAndAverageScoreOfAuthor(data)
env.execute()
}
// 按照作家划分,统计不同作家的所有专辑的销量和在各个体系中的得分
// 因为作家数量太多,取总销量前50的作家和评分的关系
def salesAndAverageScoreOfAuthor(data: DataSet[Music]): Unit = {
// 统计每位作家所有专辑的销量
val artistSaleDS: DataSet[(Int, Int)] = data.map(
element => (element.artist_id, element.sales)
).groupBy(_._1)
.reduce((x, y) => (x._1, x._2 + y._2))
.sortPartition(1, Order.DESCENDING)
val salesAndAverageScoreOfAuthorDS: DataSet[(Int, Double, Double, Double, Long)] = data.map(
// 取出原始数据中的artist_id,sales,mtv_score,rolling_stone_score,music_maniac_score
element => (element.artist_id, element.sales.toDouble, element.mtv_score, element.rolling_stone_score, element.music_maniac_score)
).join(artistSaleDS)
.where(0)
.equalTo(0) // 将每位作家所有专辑销量的DataSet与每张专辑的评分数据进行连接,连接后DataSet为(作家id,销量,评分1,评分2,评分3,该作家所有专辑总销量)
.map(
// 计算每位作家每张专辑的得分,公式为:(该专辑销量/该作家所有专辑销量)* 该专辑的三种不同评分
// 处理后的DataSet(作家id,评分1在总评分1中的大小,评分2在总评分2中的大小,评分3在总评分3中的大小,该作家所有专辑总销量)
item => (item._1._1, item._1._2 / item._2._2.toDouble * item._1._3, item._1._2 / item._2._2.toDouble * item._1._4, item._1._2 / item._2._2.toDouble * item._1._5, item._2._2.toDouble))
.groupBy(_._1)
.reduce((x, y) => (x._1, x._2 + y._2, x._3 + y._3, x._4 + y._4, x._5)) // 将相同作家的的专辑评分相加,处理后的DataSet(作家id,总评分1,总评分2,总评分3,该作家所有专辑的总销量)
.map(item => (item._1, item._2.formatted("%.1f").toDouble, item._3.formatted("%.1f").toDouble, item._4.formatted("%.1f").toDouble, item._5.toLong)) // 类型转换
.sortPartition(4, Order.DESCENDING) // 按照销量进行排序
.first(50)
salesAndAverageScoreOfAuthorDS.writeAsCsv("src/main/data/result/salesAndScoreOfAuthor.csv", "\n", ",")
}
// 按年进行划分,统计2000年至2019年每年各类型音乐专辑的销售量
def salesOfGenreAndYear(data: DataSet[Music]): Unit = {
val salesOfGenreAndYearDS: DataSet[(String, String, Long)] = data.map(
element => (element.release, element.genres, element.sales.toLong)
).groupBy(0, 1)
.reduce((x, y) => (x._1, x._2, x._3 + y._3))
salesOfGenreAndYearDS.writeAsCsv("src/main/data/result/salesOfGenreAndYear.csv", "\n", ",")
}
// 按年进行划分,统计2000年至2019年每年各类型音乐专辑的发行数量
def releaseNumOfYear(data: DataSet[Music]): Unit = {
val releaseNumOfYearDS: DataSet[(String, String, Int)] = data.map(
element => (element.release, element.genres, 1)
).groupBy(0, 1)
.reduce((x, y) => (x._1, x._2, x._3 + y._3))
.sortPartition(0, Order.DESCENDING)
releaseNumOfYearDS.writeAsCsv("src/main/data/result/releaseNumOfYear.csv", "\n", ",")
}
// 统计从2000年至2019年各类型的音乐专辑的发行数量和销量
def releaseNumAndSalesOfGenre(data: DataSet[Music]): Unit = {
val releaseNumAndSaleOfGenre: DataSet[(String, Long, Int)] = data.map(
element => (element.genres, element.sales.toLong, 1)
).groupBy(_._1)
.reduce((x, y) => (x._1, x._2 + y._2, x._3 + y._3))
.sortPartition(1, Order.DESCENDING)
releaseNumAndSaleOfGenre.writeAsCsv("src/main/data/result/releaseNumAndSalesOfGenre.csv", "\n", ",")
}
// 分析所有专辑名称,统计专辑名称中各个单词出现的频率
def frequencyOfTitle(data: DataSet[Music]): Unit = {
val wordsOfTitle: DataSet[(String, Int)] = data.flatMap(
element => element.album_title.toLowerCase.split(" ")
).map(element => (element, 1))
.groupBy(_._1)
.reduce((x, y) => (x._1, x._2 + y._2))
.sortPartition(1, Order.DESCENDING)
wordsOfTitle.writeAsCsv("src/main/data/result/frequencyOfTitle.csv", "\n", ",")
}
}
本实验采用Python语言,使用第三方库pyecharts作为可视化工具,其中pyecharts版本为1.7.0.主要采用柱状图来展现数据集处理结果。
(1)新建PyCharm工程文件DrawPic;
(2)在DrawPic工程下创建data文件夹,用于数据集处理结果;
(3)在DrawPic工程下创建main.py,用于编写代码。
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import SymbolType
import pandas as pd
# 绘制2000年至2019年每年各类型音乐专辑的发行数量
def drawReleaseNumOfYear():
releaseNumOfYear = pd.read_csv("data/releaseNumOfYear.csv", header=None, names=['Year', 'Genre', 'ReleaseNum'])
data = pd.pivot(releaseNumOfYear, index='Year', columns='Genre')
timeline = Timeline(init_opts=opts.InitOpts(width="2000px", height="800px"))
for index, year in zip(range(data['ReleaseNum'].shape[0]), data.index.tolist()):
bar = (
Bar()
.add_xaxis(data['ReleaseNum'].columns.tolist())
.add_yaxis("销量", data['ReleaseNum'].iloc[index,].tolist(), label_opts=opts.LabelOpts(position="right"))
.reversal_axis()
.set_global_opts(title_opts=opts.TitleOpts(title="%d年各类型音乐专辑发行数量" % year, pos_left="center"), legend_opts=opts.LegendOpts(pos_top="30px"), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="发行数量"), yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="音乐专辑类型")
)
)
timeline.add(bar, year)
timeline.render('releaseNumOfYear.html')
# 绘制总销量排名前50的音乐作者在不同评分体系中的得分
def drawSalesAndScoreOfArtist():
salesAndScoreOfArtist = pd.read_csv("data/salesAndScoreOfAuthor.csv", header=None,
names=['artist_id', 'mtv_score', 'rolling_stone_score', 'music_maniac_score',
'sale'])
index = [str(x) for x in salesAndScoreOfArtist['artist_id']]
bar = (
Bar(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add_xaxis(index)
.add_yaxis("发行量", salesAndScoreOfArtist['sale'].tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="2000年-2019年音乐专辑销量前50的音乐作家专辑总销量", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=90, font_size=12), name="作家id"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="销售量"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
mult_bar = (
Bar(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add_xaxis(index)
.add_yaxis("mtv_score", salesAndScoreOfArtist['mtv_score'].tolist(), stack='stack1')
.add_yaxis("rolling_stone_score", salesAndScoreOfArtist['rolling_stone_score'].tolist(), stack='stack1')
.add_yaxis("music_maniac_score", salesAndScoreOfArtist['music_maniac_score'].tolist(), stack='stack1')
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=90, font_size=12), name="作家id"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="评分"),
title_opts=opts.TitleOpts(title="2000年-2019年音乐专辑销量前50的音乐作家评分数据", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
page = Page()
page.add(bar)
page.add(mult_bar)
page.render('salesAndScoreOfArtist.html')
# 绘制2000年至2019年每年各类型音乐专辑的销售量
def drawSalesOfGenreAndYear():
salesOfGenreAndYear = pd.read_csv("data/salesOfGenreAndYear.csv", header=None, names=['Year', 'Genre', 'Sale'])
data = pd.pivot(salesOfGenreAndYear, index='Year', columns='Genre')
timeline = Timeline(init_opts=opts.InitOpts(width="2000px", height="800px"))
for index, year in zip(range(data['Sale'].shape[0]), data.index.tolist()):
bar = (
Bar()
.add_xaxis(data['Sale'].columns.tolist())
.add_yaxis("销量", data['Sale'].iloc[index,].tolist(), label_opts=opts.LabelOpts(position="right"))
.reversal_axis()
.set_global_opts(title_opts=opts.TitleOpts(title="%d年各类型音乐专辑销量" % year, pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="销量"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="音乐专辑类型")
)
)
timeline.add(bar, year)
timeline.render('salesOfGenreAndYear.html')
# 对专辑名称中出现的词绘制词云
def drawCloud():
words = pd.read_csv("data/frequencyOfTitle.csv", header=None, names=['word', 'count'])
data = [(i, j) for i, j in zip(words['word'], words['count'])]
cloud = (
WordCloud(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add("", data, word_size_range=[20, 100], shape=SymbolType.ROUND_RECT)
.set_global_opts(title_opts=opts.TitleOpts(title="2000年-2019年所有音乐专辑名称词汇统计", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
tooltip_opts=opts.TooltipOpts(is_show=True))
)
cloud.render("wordCloud.html")
# 绘制2000年至2019年各类型的音乐专辑的发行数量和销量
def drawReleaseNumAndSalesOfGenre():
releaseNumAndSalesOfGenre = pd.read_csv("data/releaseNumAndSalesOfGenre.csv", header=None,
names=['Type', 'Sale', 'Num'])
bar = (
Bar(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add_xaxis(releaseNumAndSalesOfGenre['Type'].tolist())
.add_yaxis("发行量", releaseNumAndSalesOfGenre['Num'].tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="2000年-2019年不同类型音乐专辑发行量与销量", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45, font_size=12), name="音乐专辑类型"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12),
name="发行量"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
# 添加右侧y轴
.extend_axis(
yaxis=opts.AxisOpts(
name="销量",
)
)
)
line = (
Line()
.add_xaxis(releaseNumAndSalesOfGenre['Type'].tolist())
.add_yaxis("销量",
releaseNumAndSalesOfGenre['Sale'],
yaxis_index=1,
z=2,
label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
)
bar.overlap(line).render("releaseNumAndSalesOfGenre.html")
if __name__ == '__main__':
drawReleaseNumAndSalesOfGenre()
drawCloud()
drawSalesOfGenreAndYear()
drawSalesAndScoreOfArtist()
drawReleaseNumOfYear()
执行上面可视化代码后,会在DrawPic工程下出现5个.html文件,点击浏览即可得到分析结果。
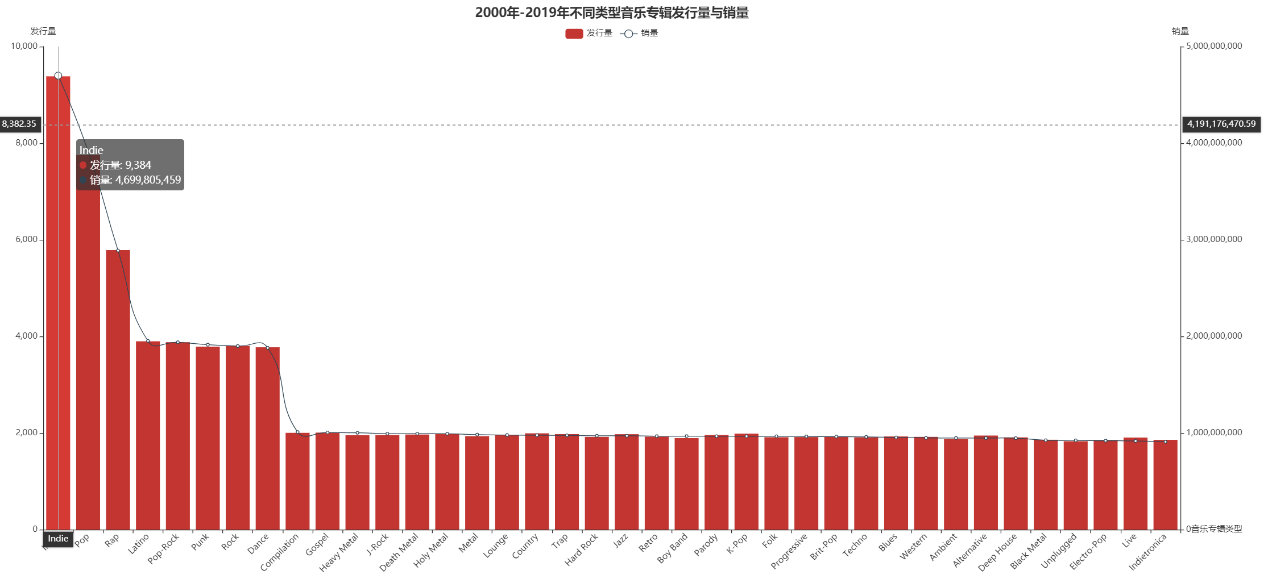
从图中可以看出,2000年至2019年各类型的音乐专辑中,Indie、Pop和Rap类型发行数量最多,同时销量也是最多。
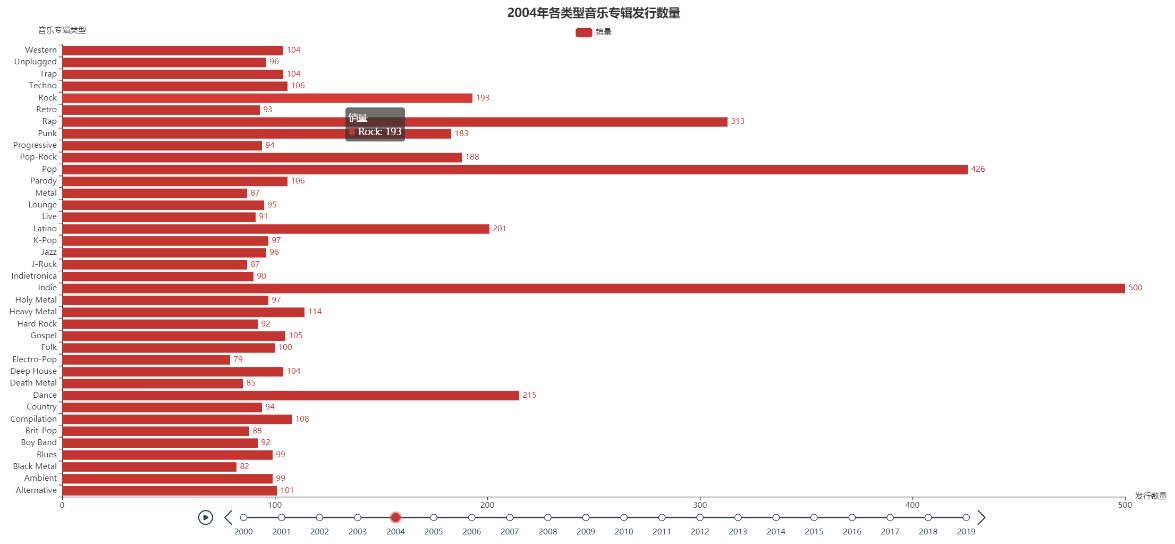
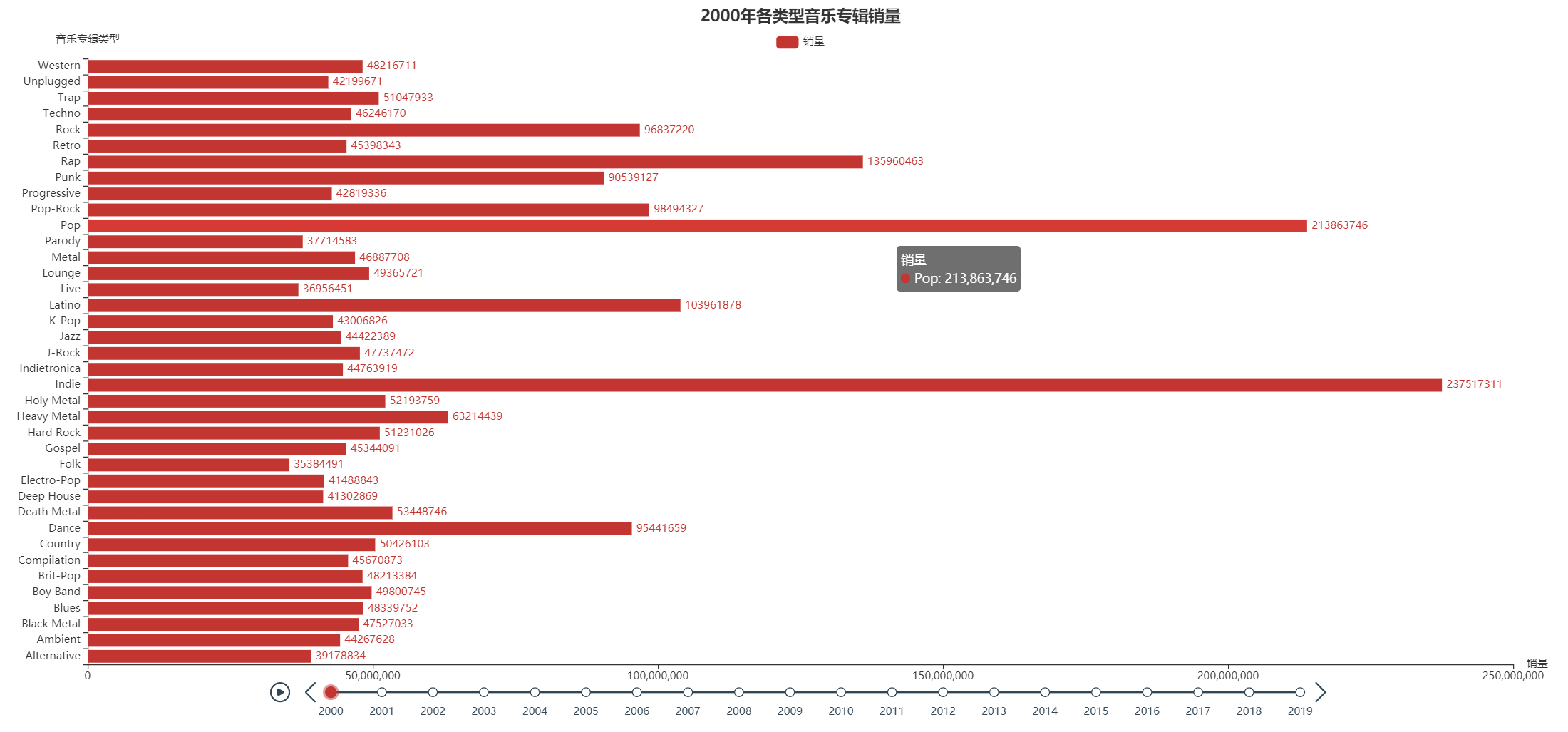
进一步对数据进行分析,按年进行划分,从上述图中显示,Indie、Pop和Rap三种类型的音乐专辑发行数量和销量在2000年至2019年中每年都是最多的,并不存在某一年某种类型专辑的发行数量和销量突然增多的情况。
获取2000年至2019年期间所有音乐专辑作家的音乐专辑总销量,按照下面的公式计算其在不同平台的得分情况: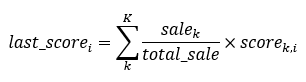
其中,last_score_i是第i个平台的最后得分,sale_k是该音乐专辑作家第k张专辑销量,total_sale是该音乐专辑作家所有专辑销量,score_k_i是该音乐专辑作家第k张专辑在第i个平台的得分。通过上述式子可以计算得出每位音乐专辑作家在不同音乐平台上的得分情况,由于数量过多,现只取总销量前50的音乐专辑作家进行分析。最后可视化结果,如下面两图所示: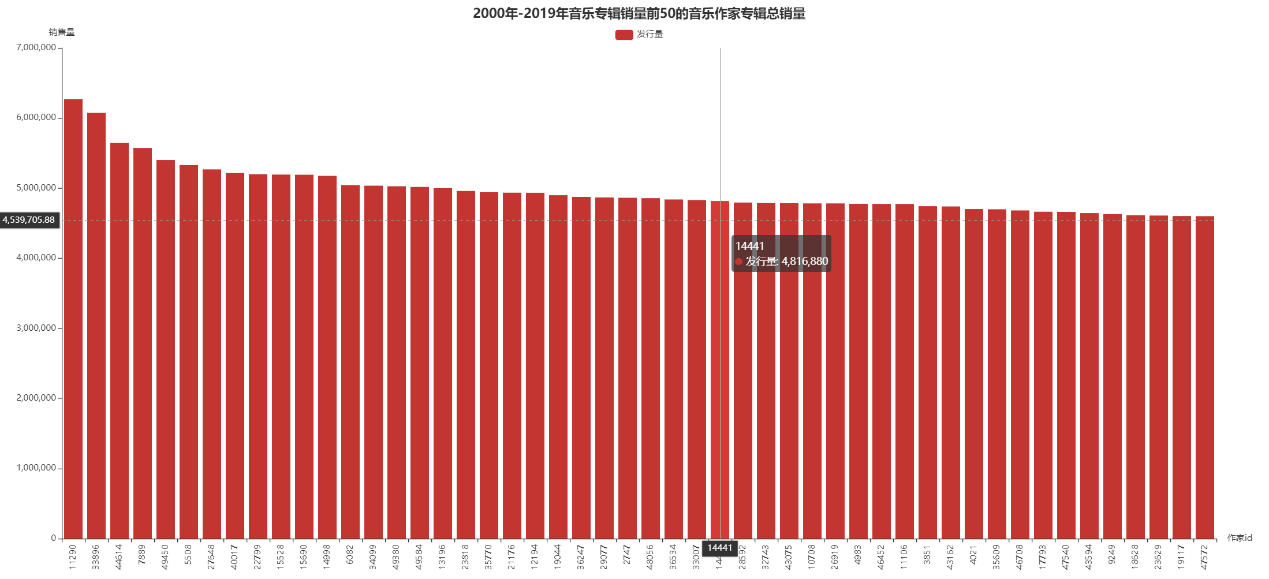
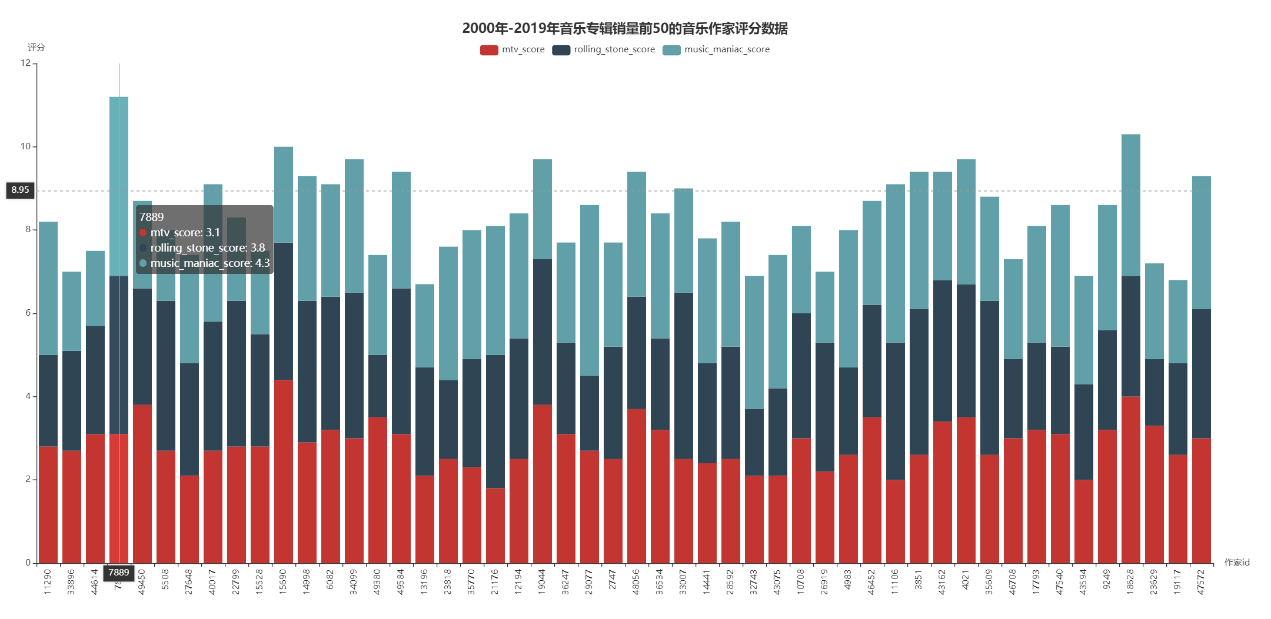
从上面两图可以看出,总销量高的音乐专辑作家的评分不一定高。